

Technical deep dive into how I built Print Nanny, which uses computer vision to automatically detect 3D printing failures.
Technical deep dive into how I built Print Nanny, which uses computer vision to automatically detect 3D printing failures. I’ll cover each development phase: from minimum viable prototype to scaling up to meet customer demand.
Launching an AI/ML-powered product as a solo founder is a risky bet. Here’s how I made the most of my limited time by defining a winning ML strategy and leveraging the right Google Cloud Platform services at each stage.
For my birthday last spring, I bought myself what every gal needs: a fused filament fabrication system (AKA a 3D printer). I assembled the printer, carefully ran the calibration routines, and broke out my calipers to inspect the test prints.
Most of my prints were flawless! Occasionally though, a print would fail spectacularly. I setup OctoPrint, which is an open-source web interface for 3D printers. I often peeked at the live camera feed, wondering if this was a small taste of what new parents felt for high-tech baby monitors.
Surely there must be a better way to automatically monitor print health?





Machine Learning Strategy
Developing an AI/ML-backed product is an expensive proposition — with a high risk of failure before realizing any return on investment.
According to a global study conducted by Rackspace in January 2021, 87% of data science projects never make it into production.
In their efforts to overcome the odds, surveyed companies spent on average $1.06M on their machine learning initiatives. As a solo founder, I wasn’t prepared to spend more than a million dollars on my idea!
Luckily, I’m part of Google’s Developer Expert program — which is full of folks who love sharing their knowledge with the world. Going into this project, I had a good idea of how I could build a prototype quickly and inexpensively by outsourcing the “undifferentiated heavy lifting” to the right cloud services.
What makes Machine Learning a risky bet?
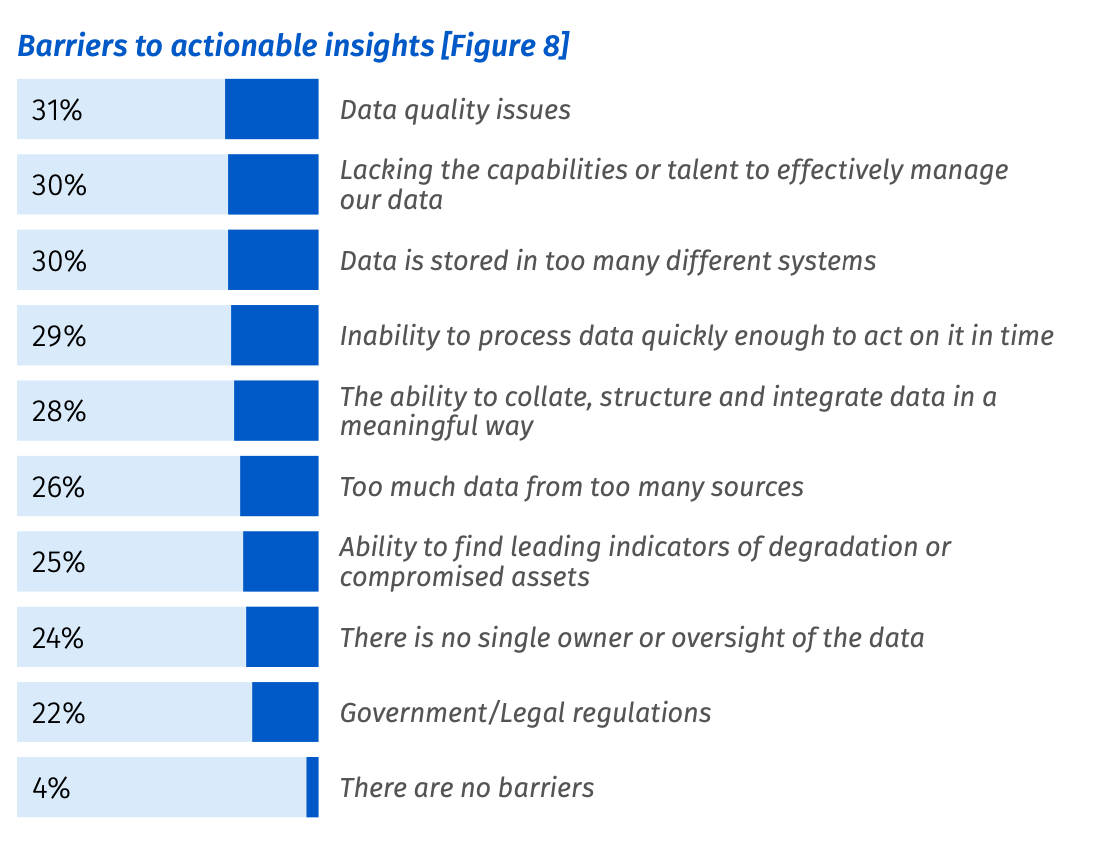
Among the 1,870 Rackspace study participants, here’s a summary of the current use, future plans, and reasons for failure reported among AI/ML projects.
A few common themes are apparent among the challenges and barriers:
- All things data: poor data quality, inaccessible data, lacking data stewardship, and inability to structure/integrate data in a meaningful way.
- Expertise and skilled talent are in short supply. The good news is: you can develop skills and intuition as you go. Everything I cover in this article can be achieved without an advanced degree!
- Lack of infrastructure to support AI/ML. I’ll show you how to progressively build data and ML infrastructure from scratch.
- Challenges in measuring the business value of AI/ML.
I’ll show you how I beat the odds (less than 1:10 chance of success) with a rapid iteration plan, made possible by leveraging the right technology and product choices at each maturity stage of an ML-powered product.
I’ll also demonstrate how I did this without sacrificing the level of scientific rigor and real-world result quality most companies spend millions attempting to achieve — all at a fraction of the cost!
Let’s dive right in. 🤓





Define Problems & Opportunities
What’s the problem? 3D printers are so gosh-darn unreliable.
That’s because 3D printer technology is still not yet mature! A few years ago, this technology was the domain of hobbyists. Industrial usage was limited to quick prototyping before committing to a more reliable manufacturing process.
Today, 3D printing is seeing more use in small-scale manufacturing. This trend was accelerated when existing manufacturing supply lines evaporated because of the COVID-19 pandemic.
An unreliable tool is a nuisance for a hobbyist but a potential liability for a small-scale manufacturing business!
In the following section, I’ll outline the problems in this space and underscore the opportunities to solve these with an AI/ML product.


Problem: 3D Printers are Unreliable 🤨
What is it that makes 3D printers so unreliable?
- Print jobs take hours (sometimes days) to complete and can fail at any moment. Requires near-constant human monitoring.
- Lacks closed-loop control of reliable industrial fabrication processes
- The most common form of 3D printing involves heating material until molten at 190°C — 220°C. This is a fire hazard if left unattended!
Human error is a factor as well.
The instructions read by 3D printers are created from hand-configured settings, using an application known as a “slicer.” Developing an intuition for the right settings takes time and patience.
Even after I decided to prototype a failure detector, the strategic line of thinking didn’t end there. I identified additional value propositions to test by with quick mock-ups, descriptive copy-writing, and surveys.
Problem: the Internet is Unreliable! 😱
Most small-scale manufacturers are operating from:
- Home (basement, garage, storage shed)
- Warehouse or industrial space
In many parts of the world, a constant upload stream from multiple cameras can saturate an internet connection — it might not be possible or economical to maintain this.
To ensure Print Nanny would still function offline, I prioritized on-device inference in the prototype. This allowed me to test the idea with zero model-serving infrastructure and leverage my research in computer vision for small devices.
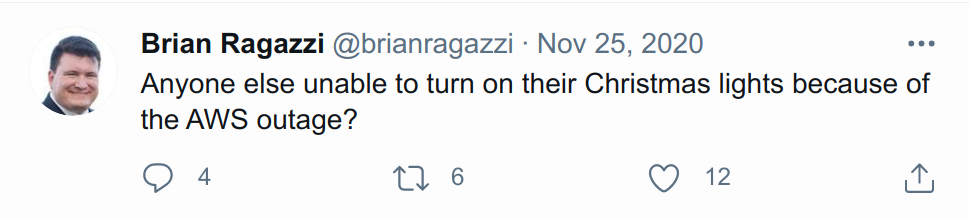
Problem: Even the Failures are Unreliable 🤪
No two 3D printing failures look alike! There are a number of reasons for this, including:
- Printer hardware is assembled by hand. The same printer model can produce wildly different results! Expert calibration is required to print uniform batches.
- Most 3D printing materials are hygroscopic (water-absorbing), resulting in batch variation and defects as volatile as the weather! 🌧️
- Many settings for slicing a 3D model into X-Y-Z movement instructions. Choosing the right settings requires trial and error to achieve the best results.
My machine learning strategy would need to allow for fast iteration and continuous improvement to build customer trust — it didn’t matter if the first prototype was not great, as long as subsequent ones showed improvement.
At all costs, to stay nimble, I’d need to avoid tactics that saddled me with a specific category of machine learning technical debt:
Changing Anything Changes Everything (CACE)
CACE is a principle proposed in Hidden Technical Debt in Machine Learning Systems, referring to the entanglement of machine learning outcomes in a system.
For instance, consider a system that uses features x1, ...xn in a model. If we change the input distribution of values in x1, the importance, weights, or use of the remaining n − 1 features may all change. This is true whether the model is retrained fully in a batch style or allowed to adapt in an online fashion. Adding a new feature xn+1 can cause similar changes, as can removing any feature xj. No inputs are ever really independent.
Zheng recently made a compelling comparison of the state ML abstractions to the state of database technology [17], making the point that nothing in the machine learning literature comes close to the success of the relational database as a basic abstraction.
Hidden Technical Debt in Machine Learning Systems
I’ll explain how I side-stepped CACE and a few other common pitfalls like unstable data dependencies in the next section. I’ll also reflect on the abstractions that saved me time and the ones which were a waste of time.



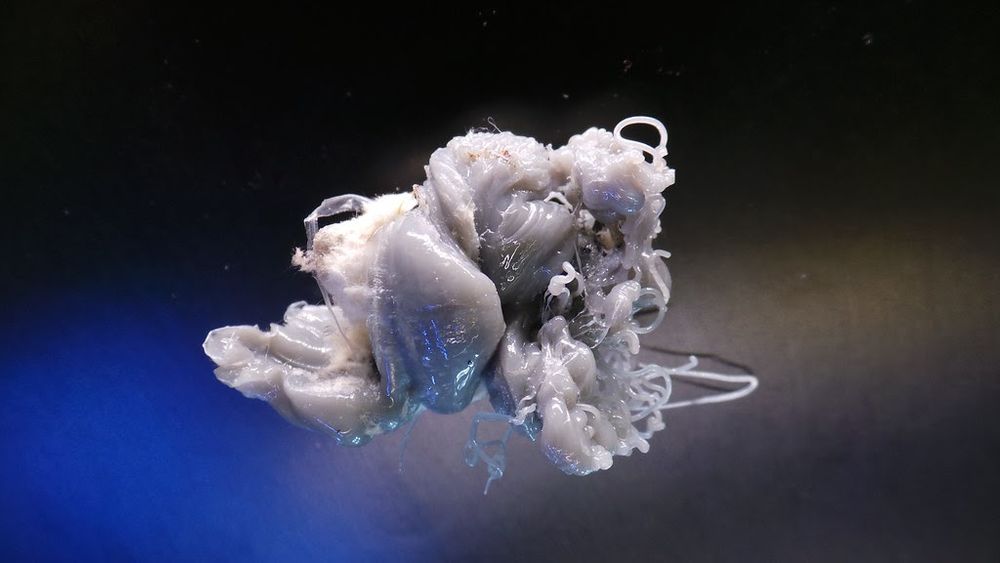
Prototype the Path
As part of developing a solid product and machine learning strategy, I “scoped the prototype down to a skateboard.” I use this saying to describe the simplest form of transportation from Point A (the problem) to Point B (where the customer wants to go).
I’ve seen machine learning projects fail by buying into / building solutions that are fully formed, like the car in the picture below. Not only is the feedback received on early iterations useless, but cancellation is also a risk before the full production run.
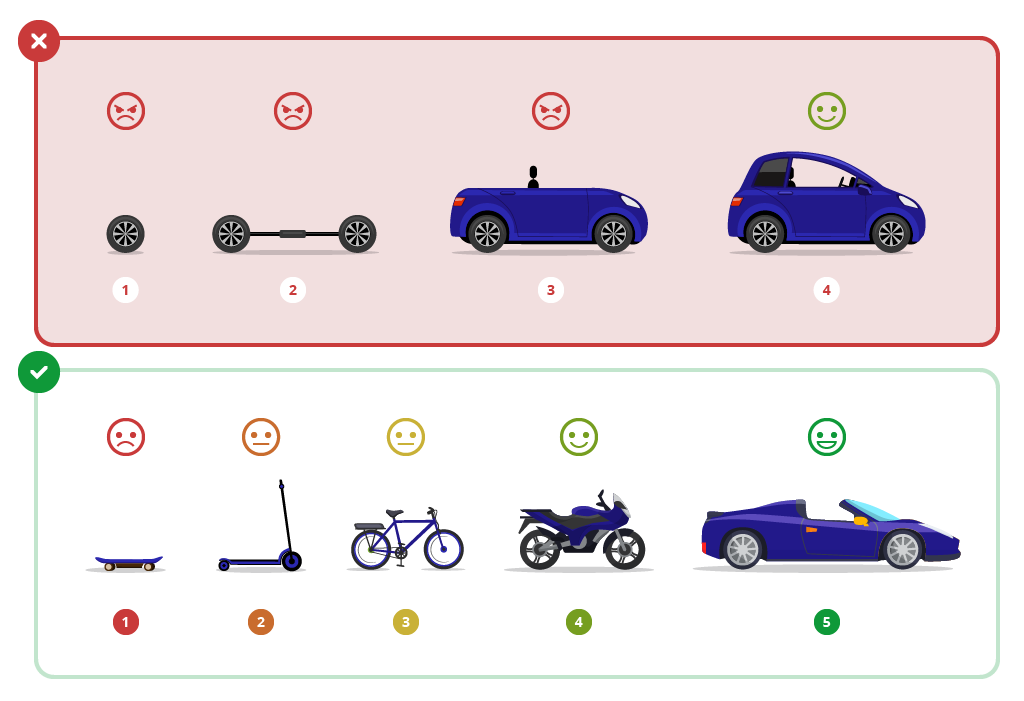
Minimum Awesome Product
Instead of building a fully-featured web app, I developed the prototype as a plugin for OctoPrint. OctoPrint provides a web interface for 3D printers, web camera controls, and a thriving community.
I distilled the minimum awesome product down to the following:
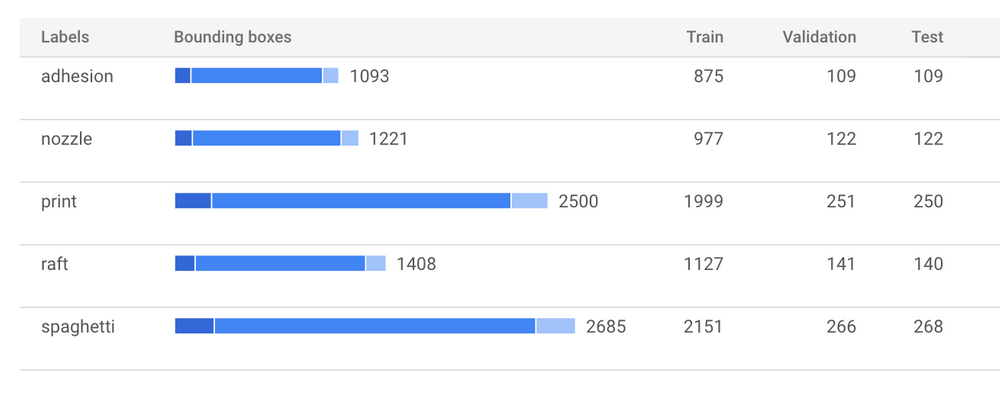
- Train model to detect the following object labels:
{print, raft, spaghetti, adhesion, nozzle} - Deploy predictor code to Raspberry Pi via OctoPrint plugin
- Calculate health score trends
- Automatically stop unhealthy print jobs.
- Provide feedback about Print Nanny’s decisions 👍👎

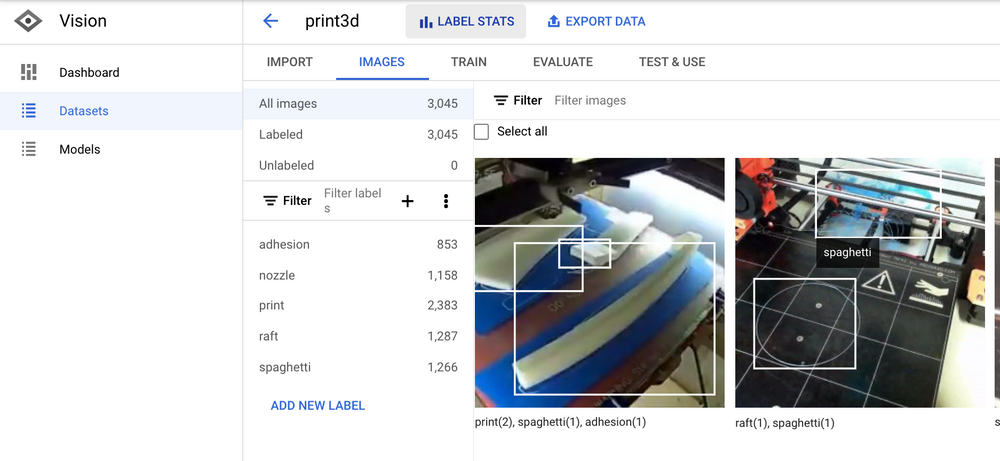
Raw Dataset
Acquiring quality labeled data is the hardest startup cost to any machine learning project! In my case, enthusiasts often upload timelapse videos to YouTube.
- Youtube-dl to download 3D print timelapse videos (pay attention to the license!)
- Visual Object Tagging Tool to annotate images with bounding boxes.
Bonus efficiency unlocked: I figured out how to automatically suggest bounding boxes in the Virtual Object Tagging Tool using a TensorFlow.js model (exported from AutoML Vision).
I explain how to do this in Automate Image Annotation on a Small Budget. 🧠
Adjusting the guidance model’s suggestions increased the number of images labeled per hour by a factor of 10, compared to drawing each box by hand.
Prepare Data for Cloud AutoML
I often use Google AutoML products during the prototype phase.
These products are marketed towards folks with limited knowledge of machine learning, so experienced data scientists might not be familiar with this product line.
Why would anyone pay for AutoML if they’re perfectly capable of training a machine learning model on their own?
Here’s why I tend to start with AutoML for every prototype:
- Upfront and fixed cost, which is way less expensive than "hiring myself"
Here's how much I paid to train Print Nanny's baseline model.

- Return on investment is easy to realize! In my experience, algorithm / model performance is just one of many contributing factors to data product success. Discovering the other factors before committing expert ML resources is a critical part of picking winning projects.
- Fast results - I had a production-ready model in under 24 hours, optimized and quantized for performance on an edge or mobile device.
Besides Cloud AutoML Vision, Google provides AutoML services for:
Tables - a battery of modeling techniques (linear, gradient boosted trees, neural networks, ensembles) with automated feature engineering.
Translation - train custom translation models.
Video Intelligence - classify video frames and segment by labels.
- Classification - predict a category/label
- Entity Extraction - extract data from invoices, restaurant menus, tax documents, business cards, resumes, and other structured documents.
- Sentiment Analysis - identify prevailing emotional opinion
Train Baseline Model
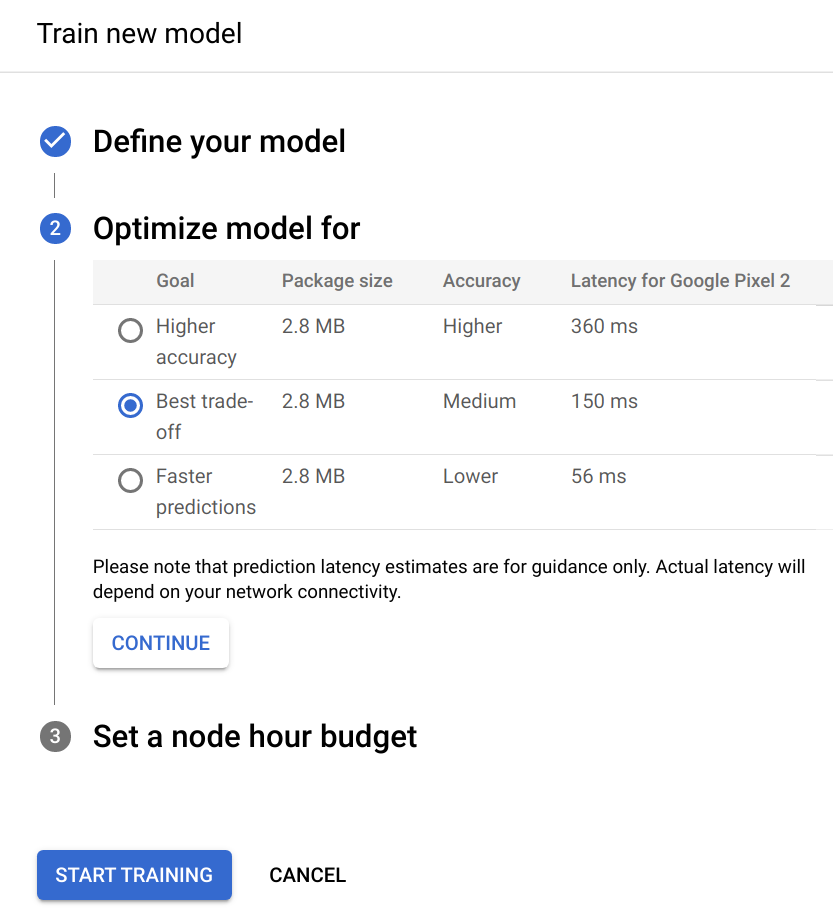
Cloud AutoML Vision Edge trains a TensorFlow model optimized for edge / mobile devices. Under the hood, AutoML's architecture & parameter search uses reinforcement learning to find the ideal trade-off between speed and accuracy.
Check out MnasNet: Towards Automating the Design of Mobile Machine Learning Models and MnasNet: Platform-Aware Neural Architecture Search for Mobile if you'd like to learn more about the inner workings of Cloud AutoML Vision!
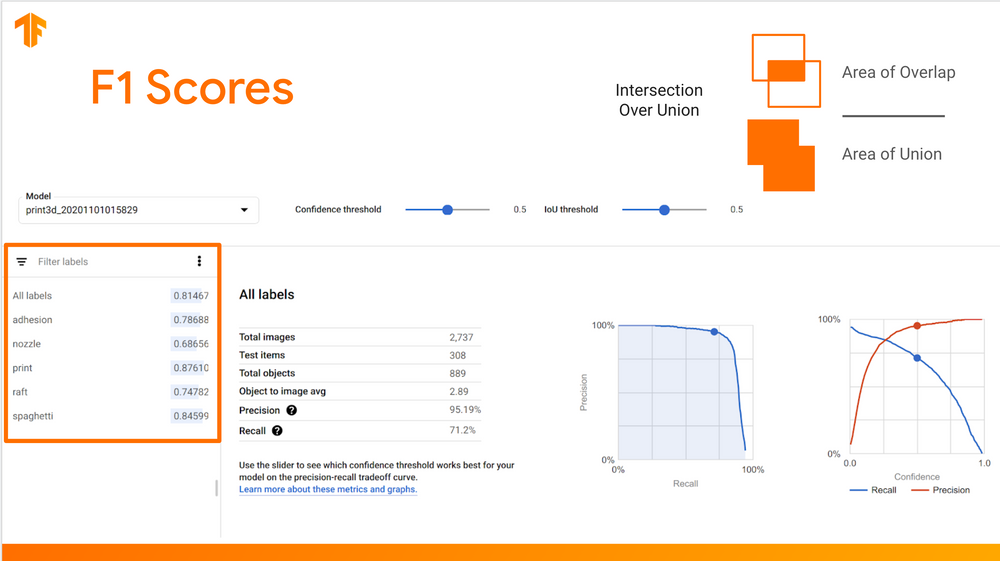
Baseline Model Metrics
You can fetch AutoML model evaluation metrics via API, which is a handy way to compare candidate models against the baseline. Check out this gist to see my full example.
from google.cloud import automl
from google.protobuf.json_format import MessageToDict
import pandas as pd
project_id = "your-project-id"
model_id = "your-automl-model-id"
# Initialize AutoMl API Client
client = automl.AutoMlClient()
# Get the full path of the model
model_full_id = client.model_path(project_id, "us-central1", model_id)
# Get all evaluation metrics for model
eval_metrics = client.list_model_evaluations(parent=model_full_id, filter="")
# Deserialize from protobuf to dict
eval_metrics = [MessageToDict(e._pb) for e in eval_metrics ]
# Initialize a Pandas DataFrame
df = pd.DataFrame(eval_metrics)Engineer Improvable Outcomes
You might remember that my baseline model had a recall rate of 75% at a 0.5 confidence and IoU threshold. In other words, my model failed to identify roughly 1/4 objects in the test set. The real-world performance was even worse! 😬
Luckily, offloading baseline model training to AutoML gave me time to think deeply about a winning strategy for continuous model improvement. After an initial brainstorm, I reduced my options to just 2 (very different) strategies.
Option #1 - Binary Classifier
The first option is train a binary classifier to predict whether or not a print is failing at any single point in time: predict { fail, not fail }.
The decision to alert is based on the confidence score of the prediction. 🔔
Option #2 - Time Series Ensemble
The second option trains a multi-label object detector on a mix of positive, negative, and neural labels like { print, nozzle, blister }.
Then, a weighted health score is calculated from the confidence of each detected object.
Finally, a polynomial (trend line) is fit on a time-series view of health scores.
The decision to alert is based on the direction of the polynomial's slope and distance from the intercepts. 🔔
Binary classification is considered the "hello world" of computer vision, with ample examples using the MNIST dataset (classifying hand-written digits). My personal favorite is fashion mnist, which you can noodle around with in a Colab notebook.
Unable to resist some good science, I hypothesized most data scientists and machine learning engineers would choose to implement a binary classifier first.


Most** data scientists and machine learning engineers voted for option #1! **Study awaiting peer review and pending decision 🤣
Against the wisdom of the crowd: why did I choose to implement option 2 as part of my winning machine learning strategy?
Option 1: Changing Anything Changes Everything (CACE)
To recap, a binary classifier predicts whether or not a print is failing at any single point in time: predict { fail, not fail }.
The model learns to encode a complex outcome, which has many determinants in the training set (and many more not yet seen by the model).
To improve this model, there are only few levers I can pull:
- Sample / label weight
- Optimizer hyper parameters, like learning rate
- Add synthetic and/or augmented data
Changing any of the above changes all decision outcomes!
Option 2 - Holistic understanding of the data
The second option has more moving pieces, but also more opportunities to introspect the data and each modeled outcome.
The components are:
- Multi-label object detector (MnasNet or MobileNet + Single-shot Detector).
- Health score, weighted sum of detector confidence.
- Fit polynomial (trend line) over a health score time-series.
Instead of answering one complex question, this approach builds an algorithm from a series of simple questions:
- What objects are in this image frame?
- Where are the objects located?
- How does confidence for "defect" labels compare to neutral or positive labels? This metric is a proxy for print health.
- Where is the point of no return for a failing print job?
- Is health score holding constant? Increasing? Decreasing? How fast (slope) and when did this change start occurring? (y-intercept).
- How does sampling frequency impact the accuracy of the ensemble? Can I get away with sending fewer image frames over the wire?
Each component can be interpreted, studied, and improved independently - and doing so helps me gain a holistic understanding of the data and draw additional conclusions about problems relevant to my business.
The additional information is invaluable on my mission to continuously improve and build trust in the outcomes of my model.
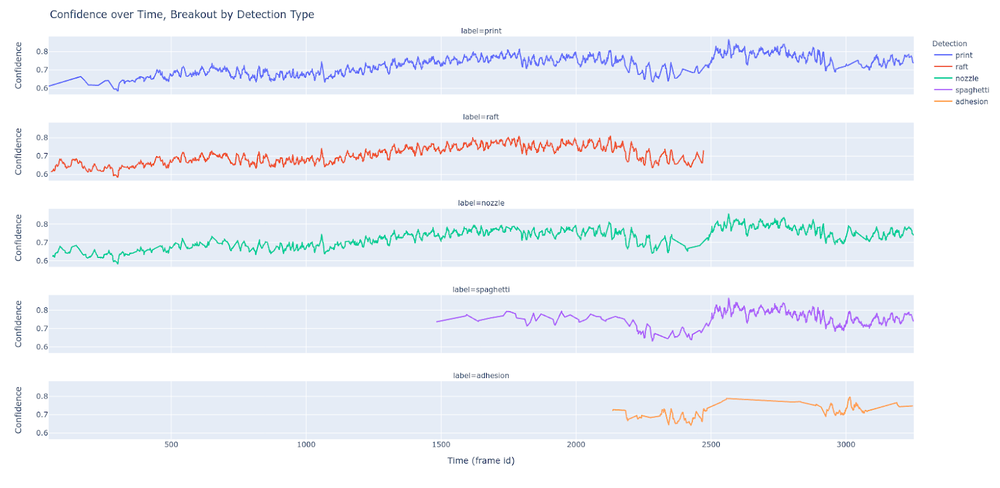
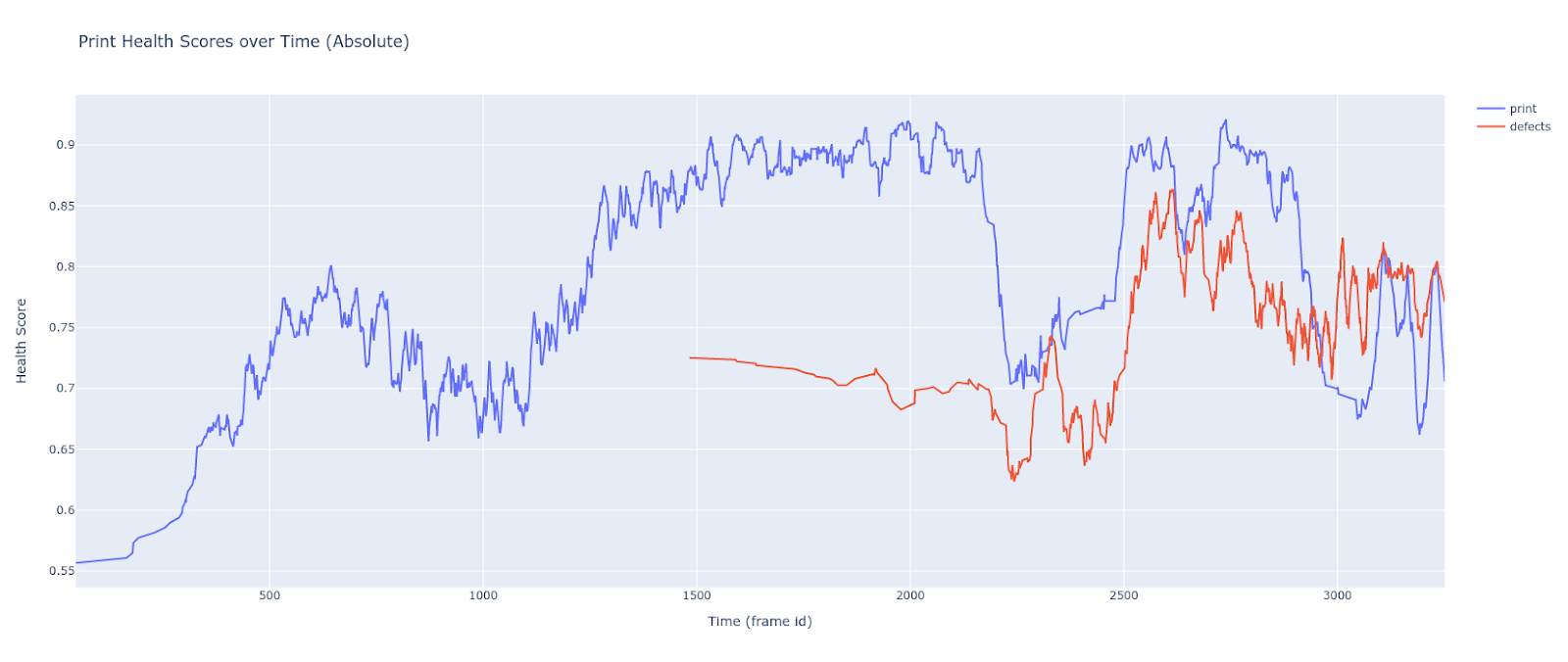

Deploy the Prototype
The first prototype of Print Nanny launched after less than 2 weeks of development, and saw worldwide adoption within days. 🤯
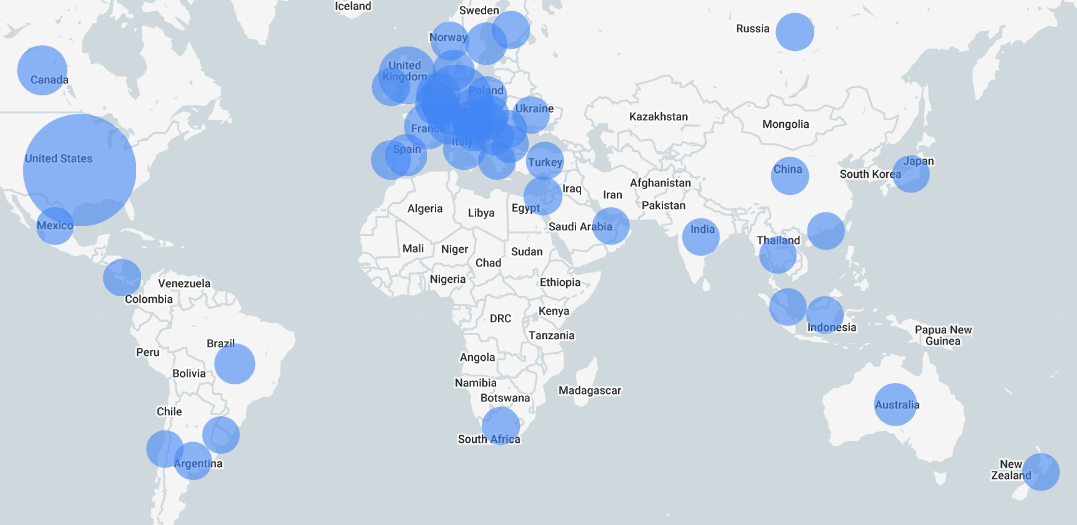
I used the following tools, tech stack, and services to deploy a proof of concept:
- Django, Django Rest Framework, and Cookiecutter Django to create web application managing closed Beta signups and invitations.
- Hyper Bootstrap theme for a landing page and UI elements.
- Google Kubernetes Engine to host the webapp.
- Cloud SQL for PostgreSQL for a database with automatic backups.
- Google Memorystore (Redis) for Django's build-in cache.
- Google Cloud AutoML Vision for Edge to train a low-cost and low-effort computer vision model optimized for mobile devices.
- TensorFlow Lite model deployed to a Raspberry Pi, packaged as a plugin for OctoPrint.
Tip: learning a web application framework will enable you test your ideas in front of your target audience. Two Scoops of Django by Daniel Feldroy & Audrey Foldroy is a no-nonsense guide to the Django framework. 💜
Green-lighting the Next Phase
After two weeks (and for a few hundred bucks), I was able to put my prototype in front of an audience and begin collecting feedback. A few vanity metrics:
- 3.7k landing page hits
- 2k closed Beta signups
- 200 invitations sent (first cohort)
- 100 avg. daily active users - wow!
Besides the core failure detection system, I tested extremely rough mockups to learn more about the features that resonated with my audience.
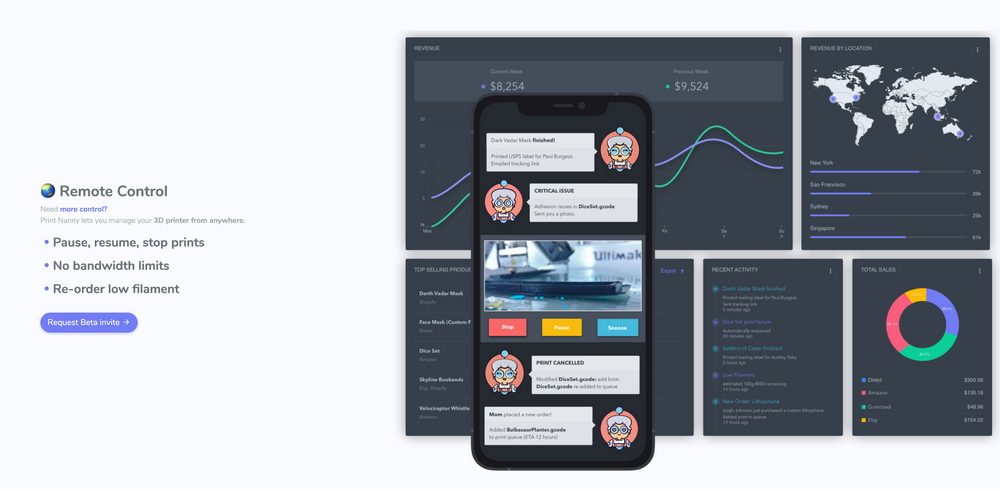
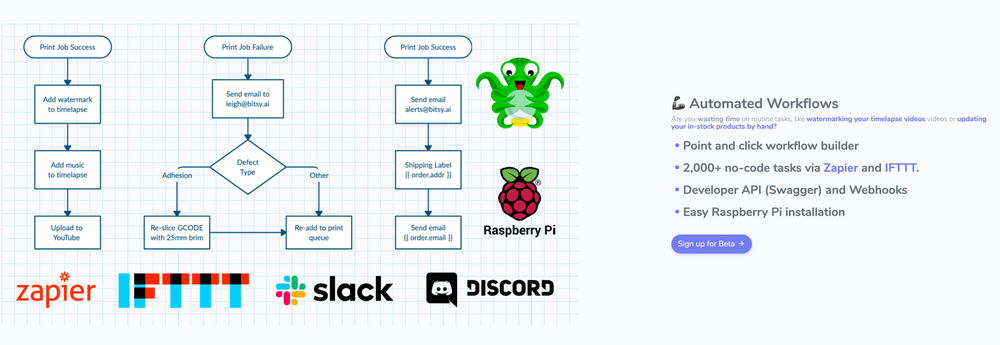
Refine Results, Add Value
The next section focuses on building trust in machine learning outcomes by refining the model's results and handling edge cases.
Build for Continuous Improvement
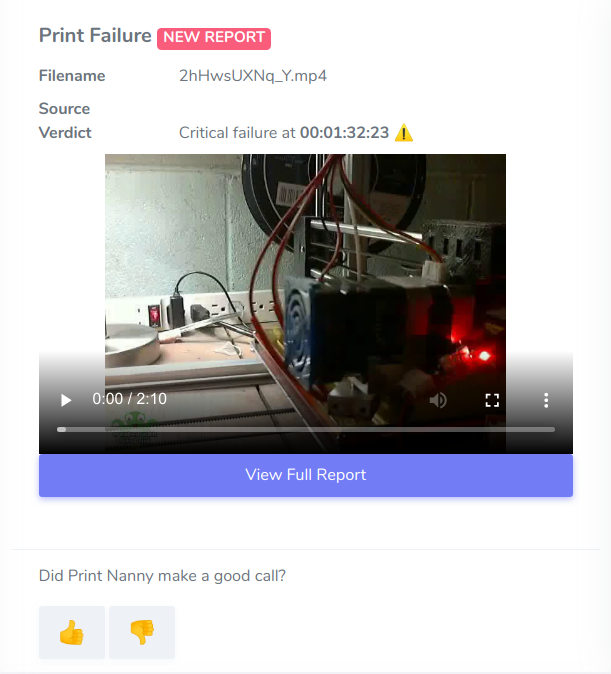
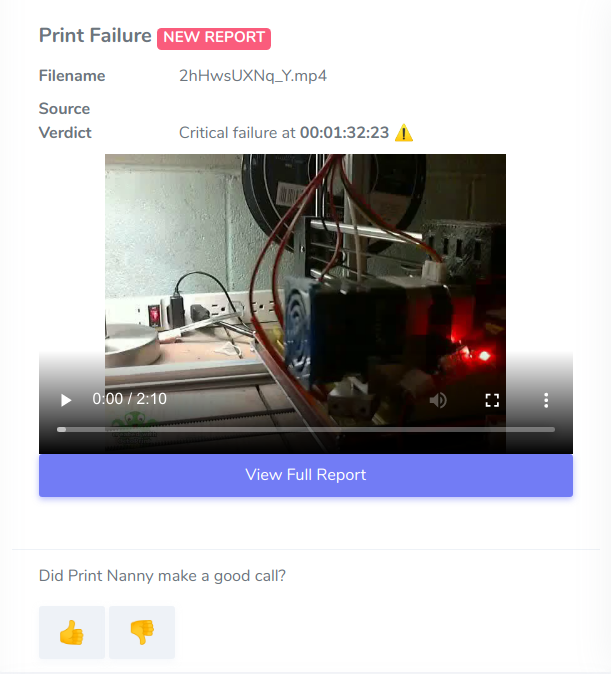
Two feedback mechanisms are used to flag opportunities for learning:
- When a failure is detected: "Did Print Nanny make a good call?" 👍 👎
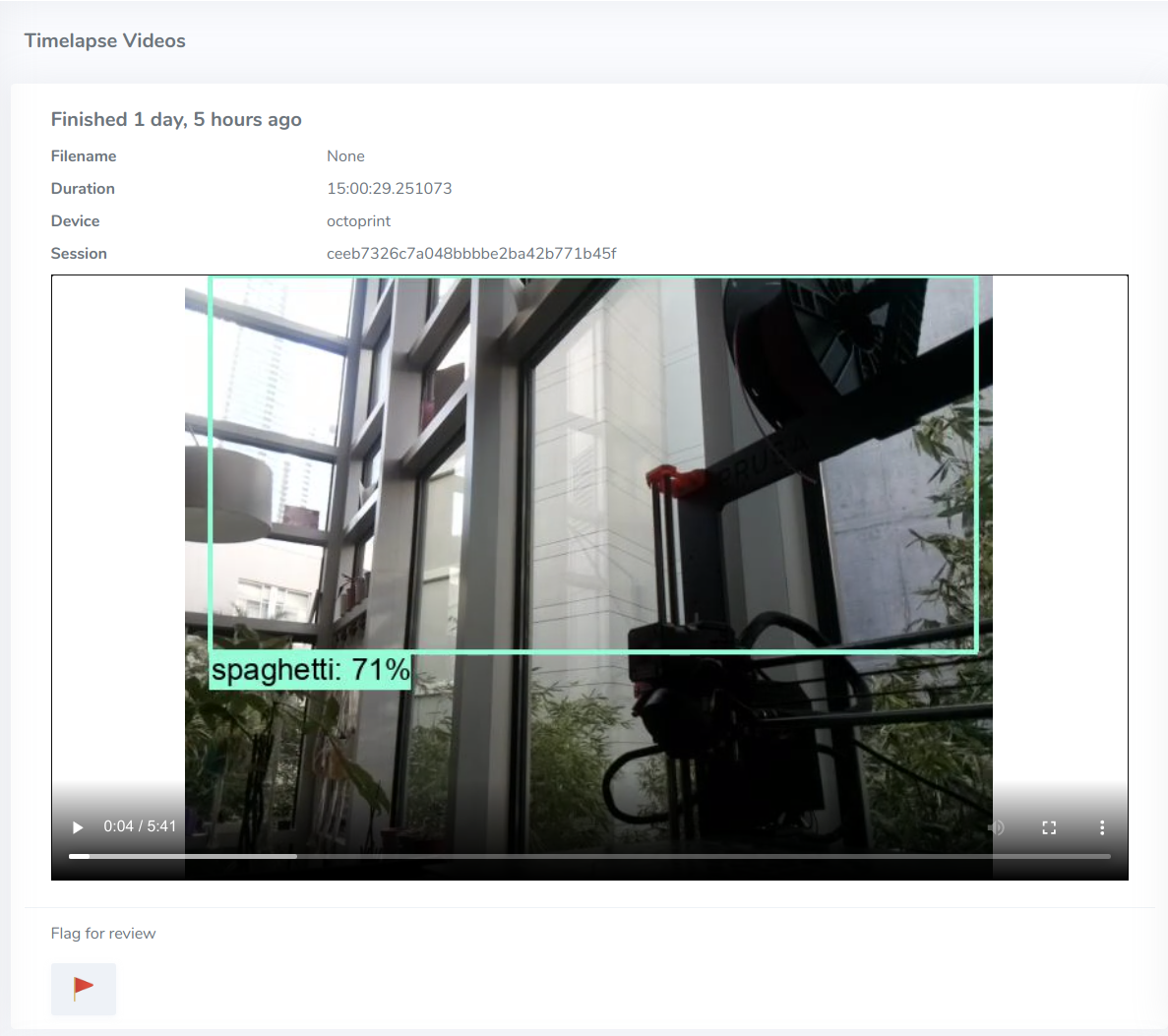
- Any video can be flagged for additional review 🚩
At this phase, I'm sending flagged videos off to a queue to be manually annotated and incorporated into a versioned training dataset.
I keep track of aggregate statistics about the dataset overall and flagged examples.
- Mean, median, mode, standard deviation of RGB channels
- Subjective brightness (also called relative luminance)
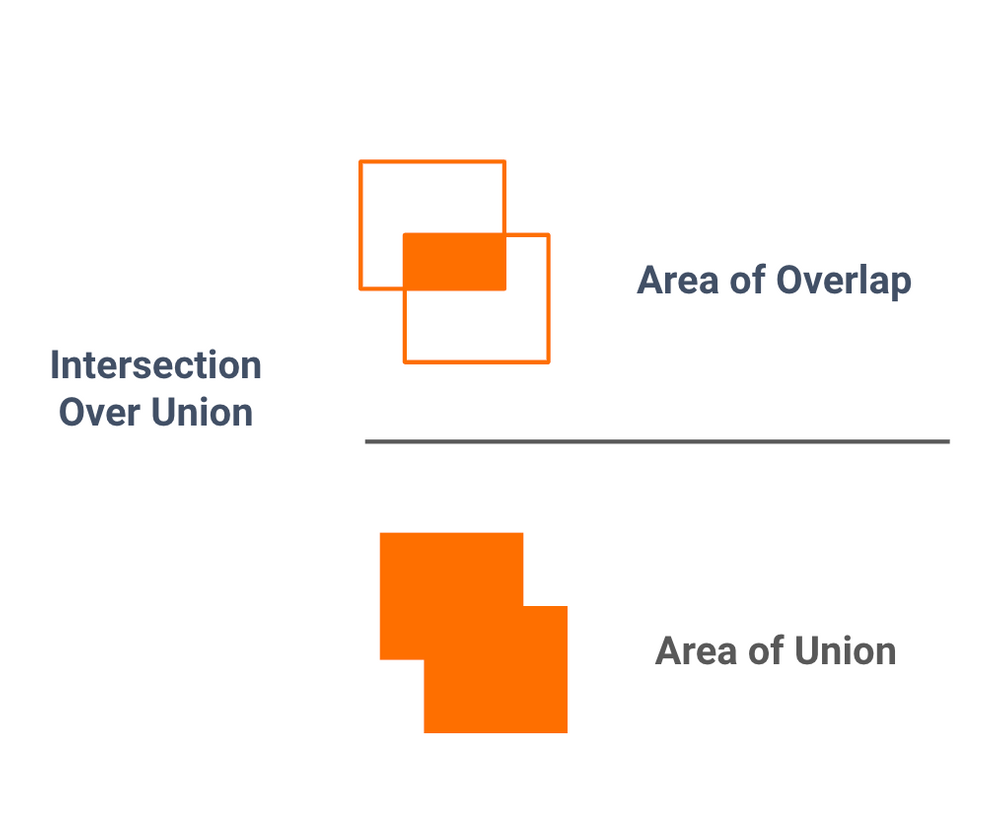
- Mean average precision with respect to intersection over union, with breakouts per label and among boxes with small dimensions (1/10 total area) vs large boxes (1/4 total area).
mAP iou = 0.5, mAP iou = 0.75, mAP small/large
This lets me understand if my model is under-performing for certain lighting conditions, filament colors, and bounding box size - broken down per label.
Restrict Area of Interest
Soon after I deployed the prototype, I realized value from the flexibility of my failure detection ensemble. When I developed the model, I hadn't considered that most 3D printers are built with 3D-printed components. 🤦♀️
I added the ability to select an area of interest and excluded objects outside from health score calculations.

Ingest Telemetry Data
How did I go from on-device predictions to versioned datasets organized neatly in Google Cloud Storage?
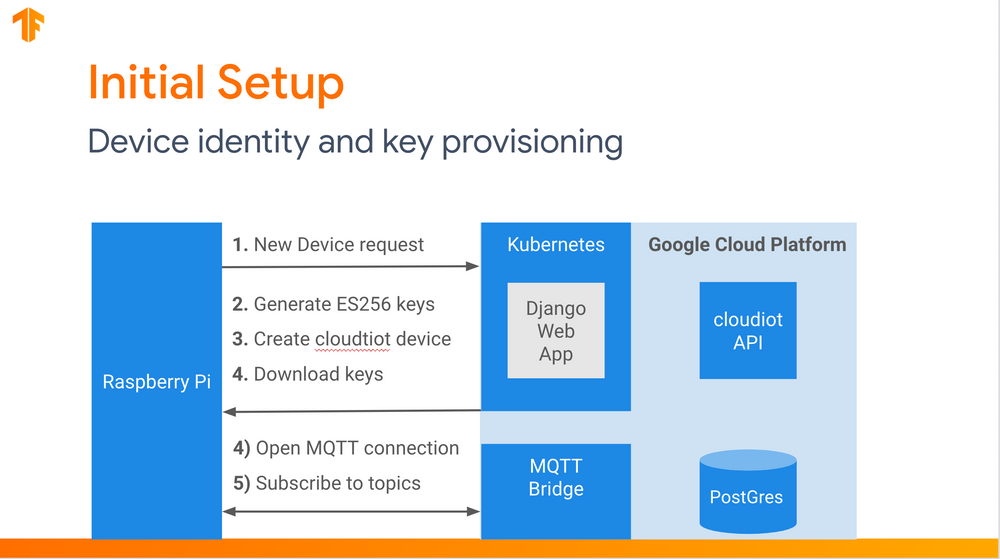
At first, I handled telemetry events with a REST API. It turns out, REST is not that great for a continuous stream of events over a very-unreliable connection. Luckily, there is a protocol designed for IoT use-cases called MQTT.
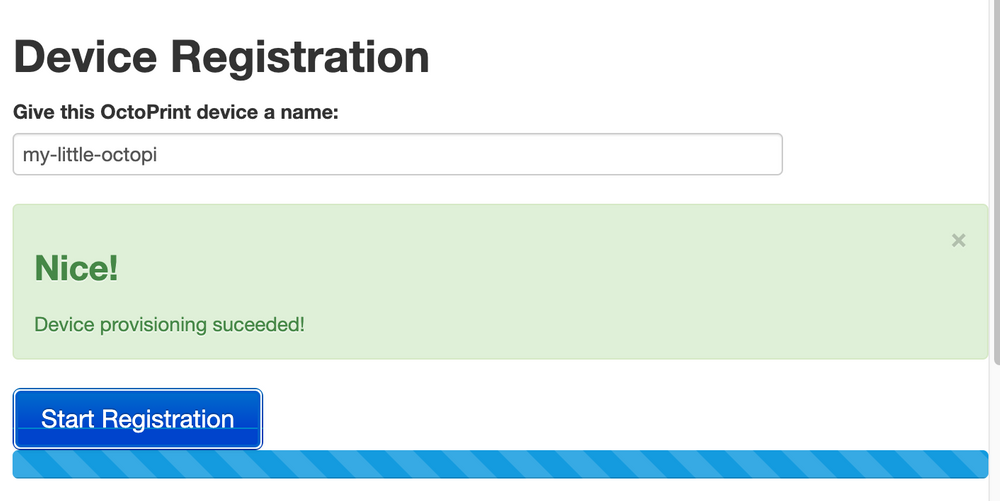
I used Cloud IoT Core to manage Raspberry Pi device identity and establish two-way device communication using MQTT message protocol.
MQTT describes three Quality of Service (QoS) levels:
- Message delivered at most once - QoS 0
- Message delivered at least once - QoS 1
- Message delivered exactly once - QoS 2
Note: Cloud IoT does not support QoS 2!
Besides whisking away the complexity of managing MQTT infrastructure (like load-balancing and horizontal scaling), Cloud IoT Core provides even more value:
- Device Registry (database of device metadata and fingerprints).
- JSON Web Token (JWT) authentication with HMAC signing.
- MQTT messages automatically republished to Pub/Sub topics.
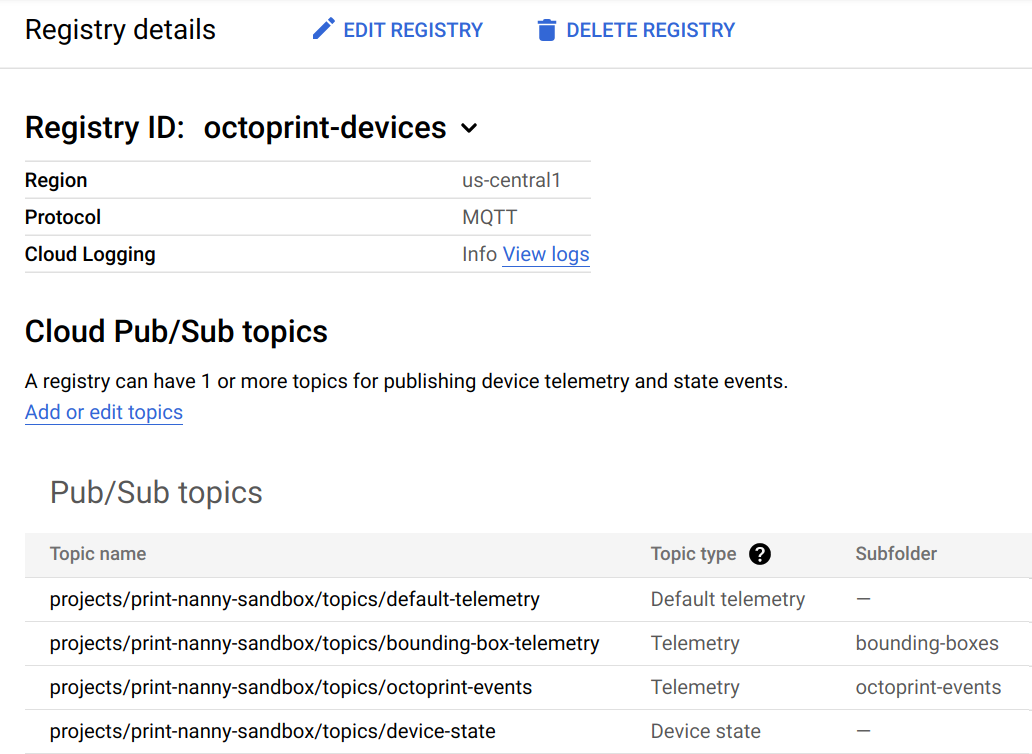
After device telemetry messages reach Cloud Pub / Sub, integration into many other cloud components and services is possible.

Data Pipelines & Data Lake
Print Nanny's data pipelines are written with Apache Beam, which supports writing both streaming and batch processing jobs. Beam is a high-level programming model, with SDKs implemented in Java (best), Python (getting there), and Go (alpha). The Beam API is used to build a portable graph of parallel tasks.
There are many execution engines for Beam (called runners). Cloud Dataflow is a managed runner, with automatic horizontal auto-scaling. I develop pipelines with Beam's bundled DirectRunner locally, then push a container image for use with Cloud Dataflow.
I could easily go on for a whole blog post (or even series) about getting started with Apache Beam! Comment below if you'd be interested in reading more about writing machine learning pipelines with TensorFlow Extended (TFX) and Apache Beam.
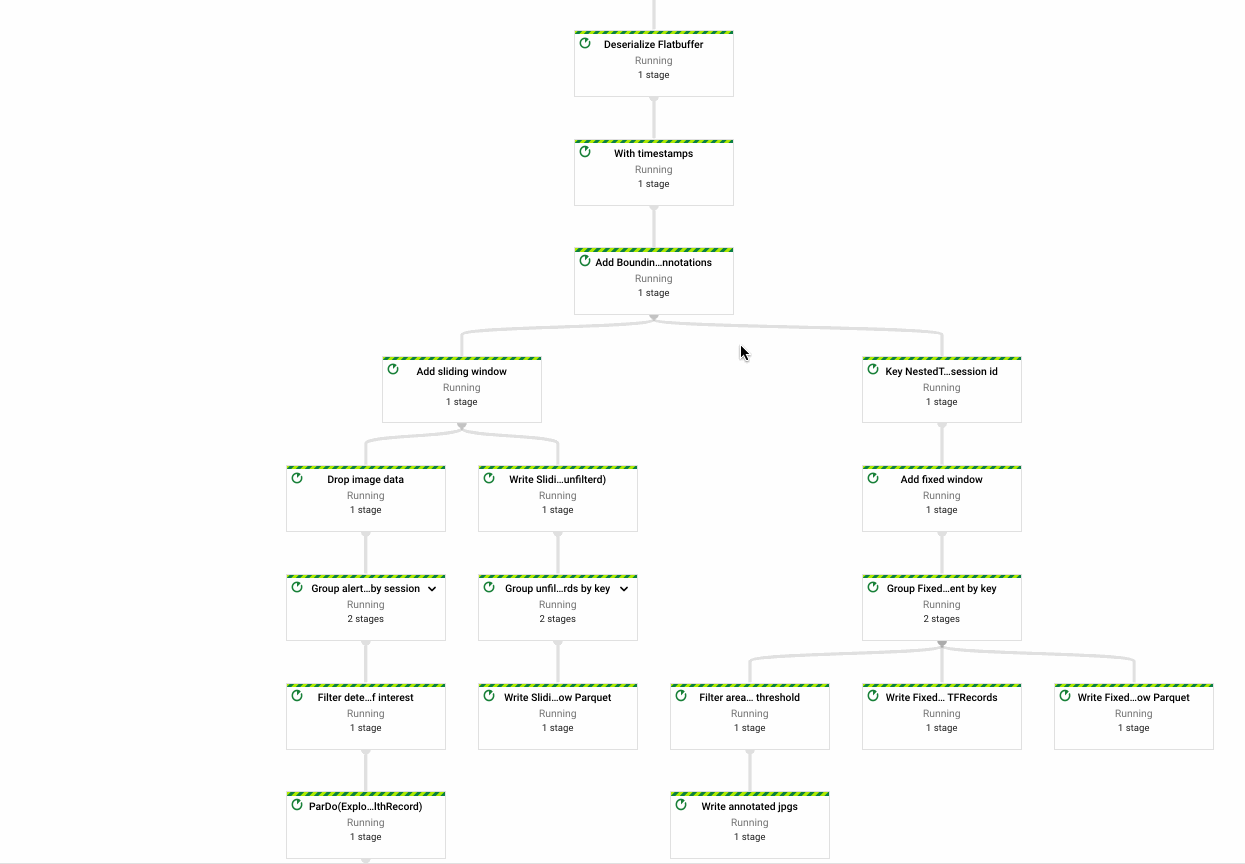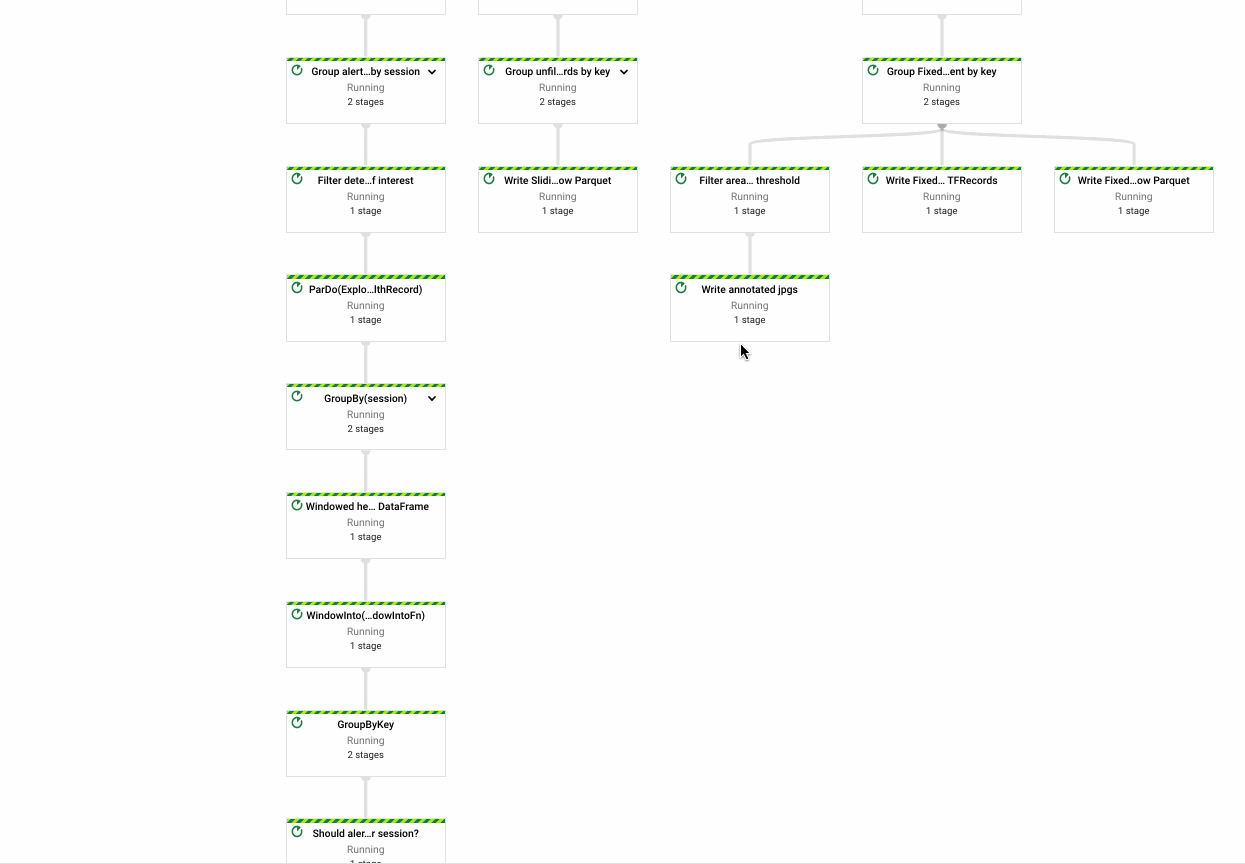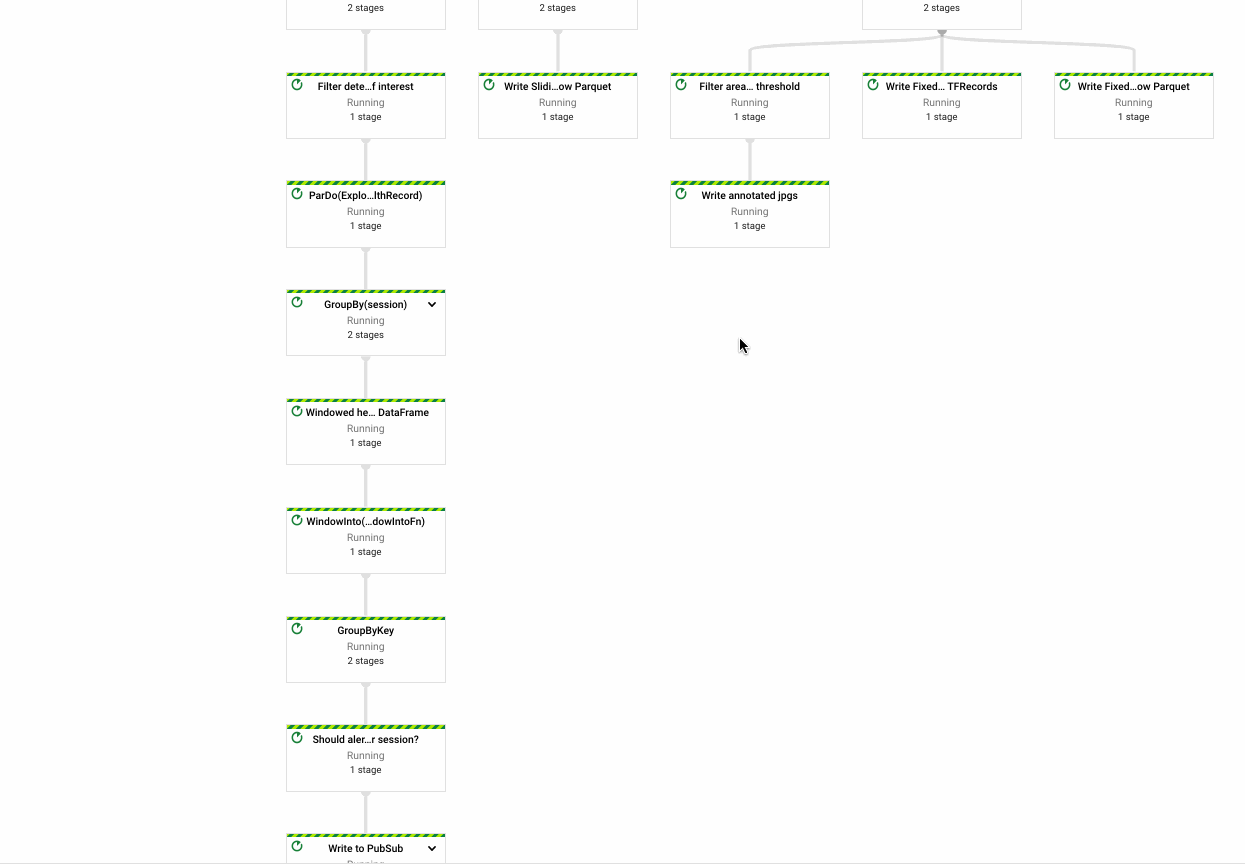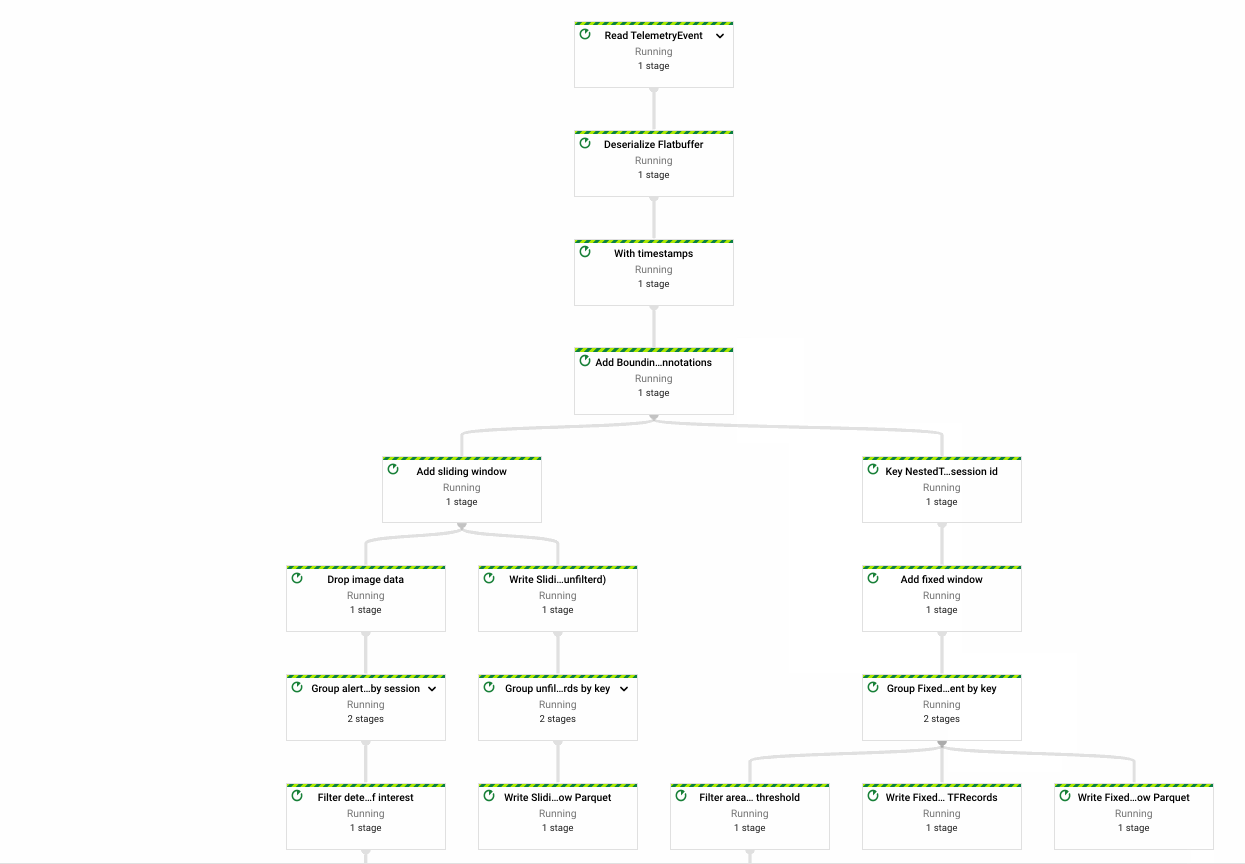
Pipelines flow into a Data Lake
My first pipeline (left) is quite large - that's ok! I'll end up breaking it apart into more common components as needed.
The key functionality of this pipeline:
- Reading device telemetry data from Pub/Sub
- Windowing and enriching data stream with device calibration and other metadata
- Packing TF Records and Parquet tables
- Writing raw inputs and windowed views to Google Cloud Storage
- Maintaining aggregate metrics across windowed views of the data stream.
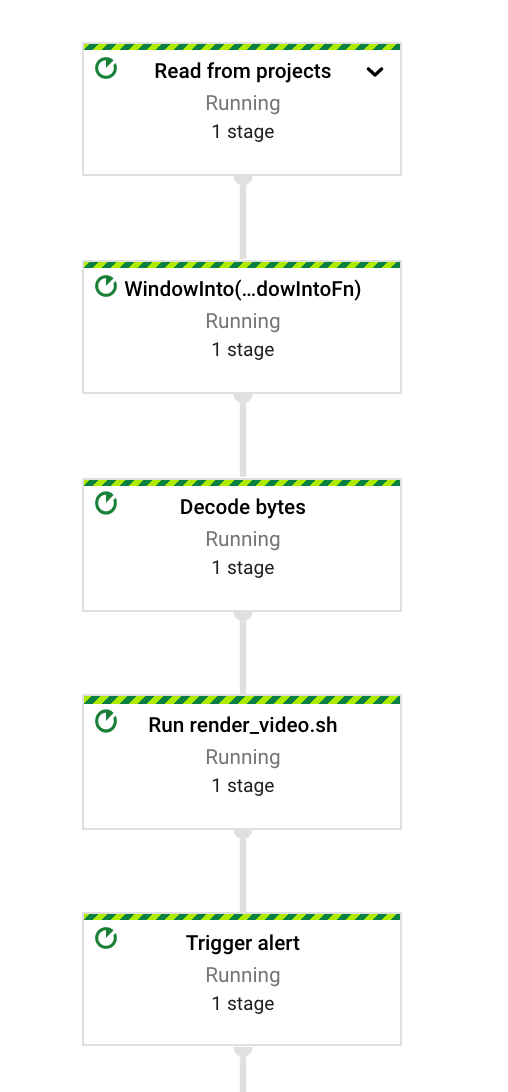
On the right is a simpler pipeline, which renders .jpg files into an .mp4 video.
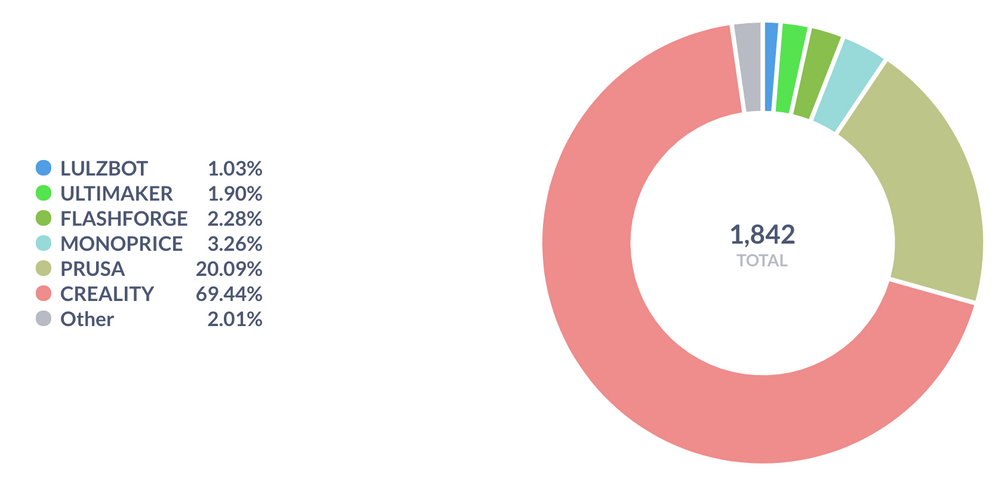
Additional AutoML Model Training
When scaling up a prototype, I try to get a sense for the qualitative impact of performance improvement from the perspective of my customers. Without this anchor, it's easy to fall into the trap of early optimization.
In my experience, improving a performance indicator is the easy part - the hard part is understanding:
- Is the performance indicator / metric a good proxy for actual or perceived value?
- If not... why does this metric not reflect real-world value? Can I formulate and study a more expressive metric?
- When will I see diminishing returns for the time invested?
I leveraged Cloud AutoML Vision again here, this time training on a blended dataset from the beta cohort and YouTube.
At this stage, I manually analyzed slices of the data to understand if the system underperforms on certain printer models or material types.
Training an Object Detector
Finally! This is where the real machine learning begins, right?
TensorFlow Model Garden
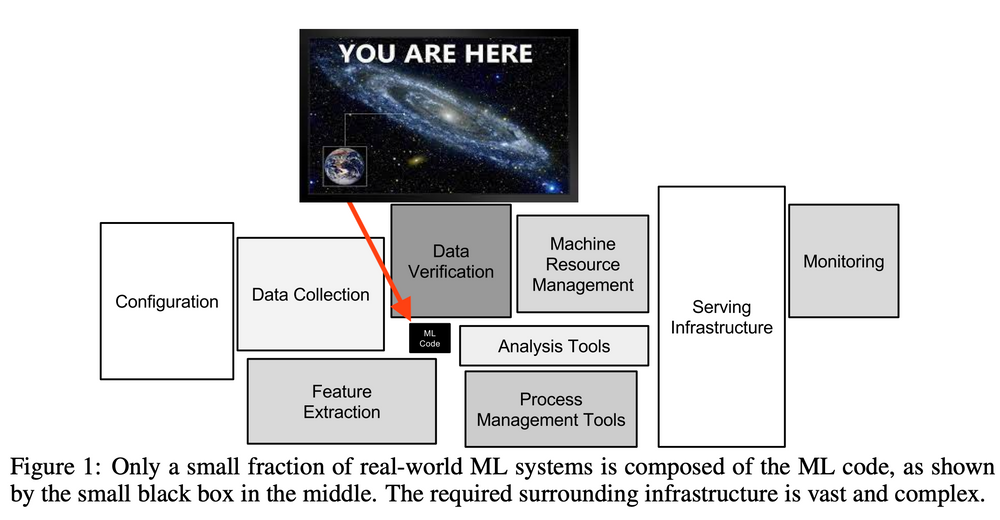
I started from TensorFlow's Model Garden. This repo contains reference implementations for many state-of-the-art architectures, as well as a few best practices for running training jobs.
The repo is divided into collections, based on the level of stability and support:
- Official. Officially maintained, supported, and kept up to date with the latest TensorFlow 2 APIs by TensorFlow, optimized for readability and performance
- Research. Implemented and supported by researchers, TensorFlow 1 and 2.
- Community. Curated list of external Github repositories.
FYI: TensorFlow's official framework for vision is undergoing an upgrade!
The examples below refer to the Object Detection API, which is a framework in the research collection.
Object Detection API
TensorFlow 2 Detection Model Zoo is a collection of pre-trained models (COCO2017 dataset). The weights are a helpful initialization point, even if your problem is outside of the domain covered by COCO
My preferred architecture for on-device inference with Raspberry Pi is a MobileNet feature extractor / backbone with a Single-Shot Detector head. The ops used in these are compatible with the TensorFlow Lite runtime.
Check out the Quick Start guide if you'd like to see examples in action.
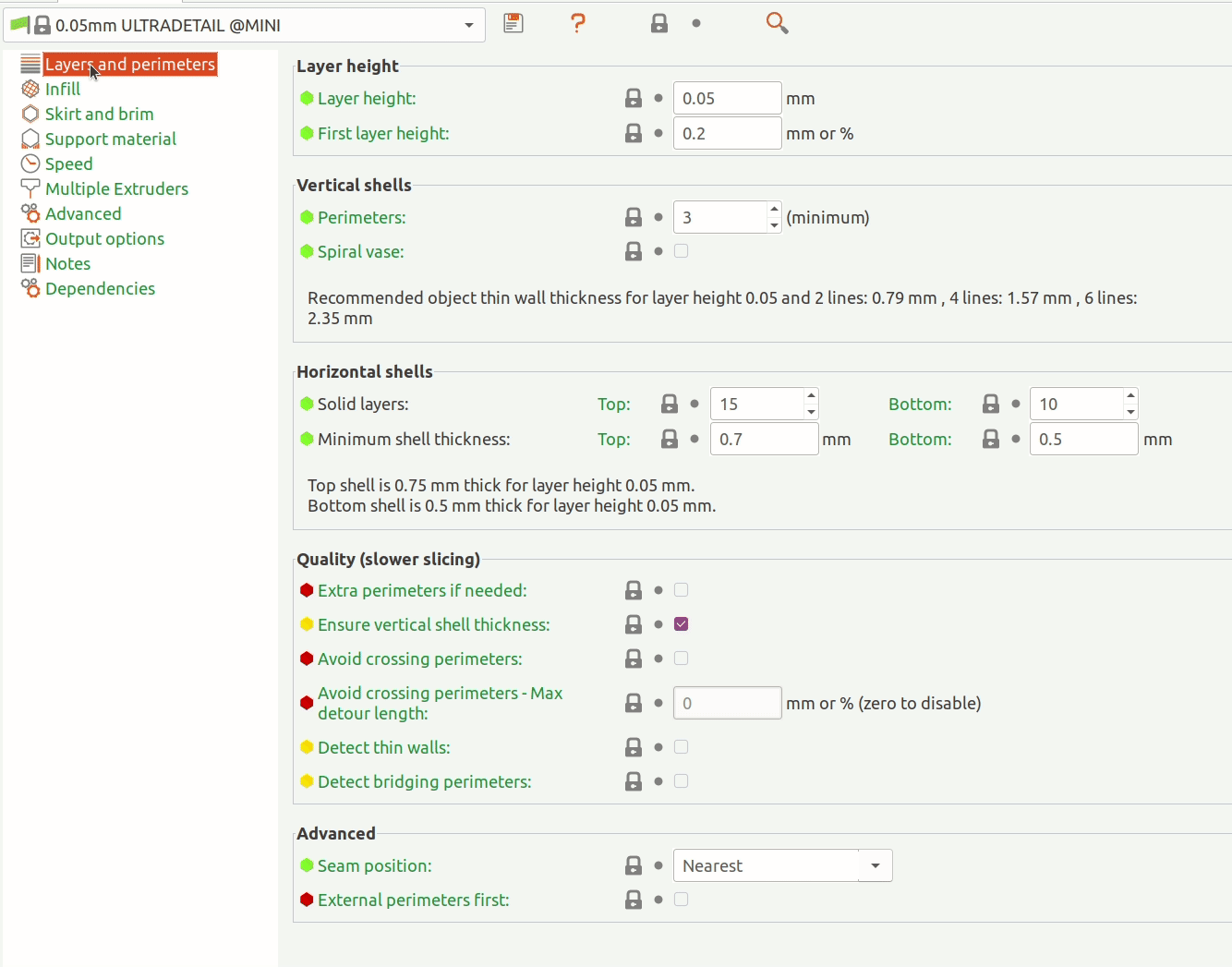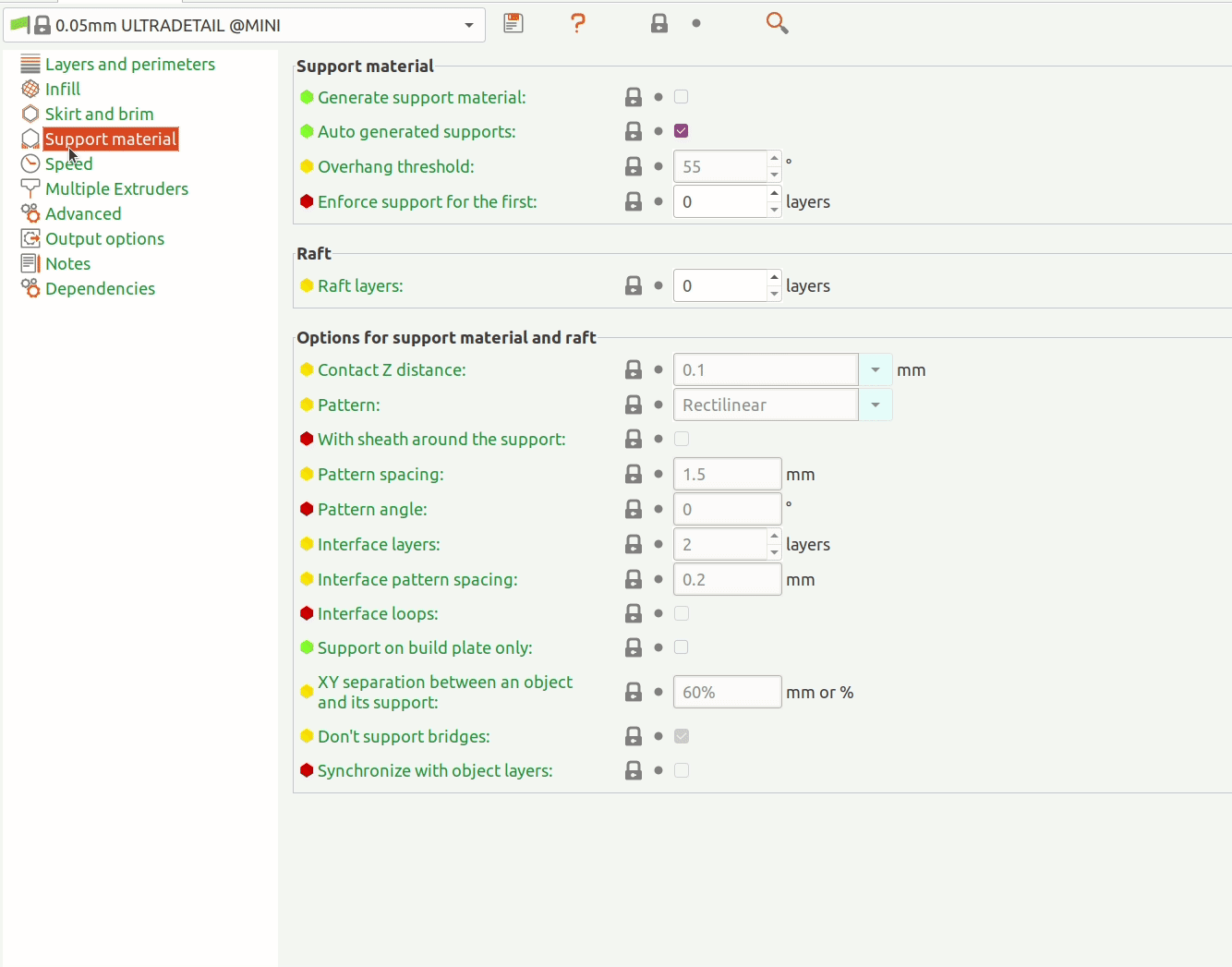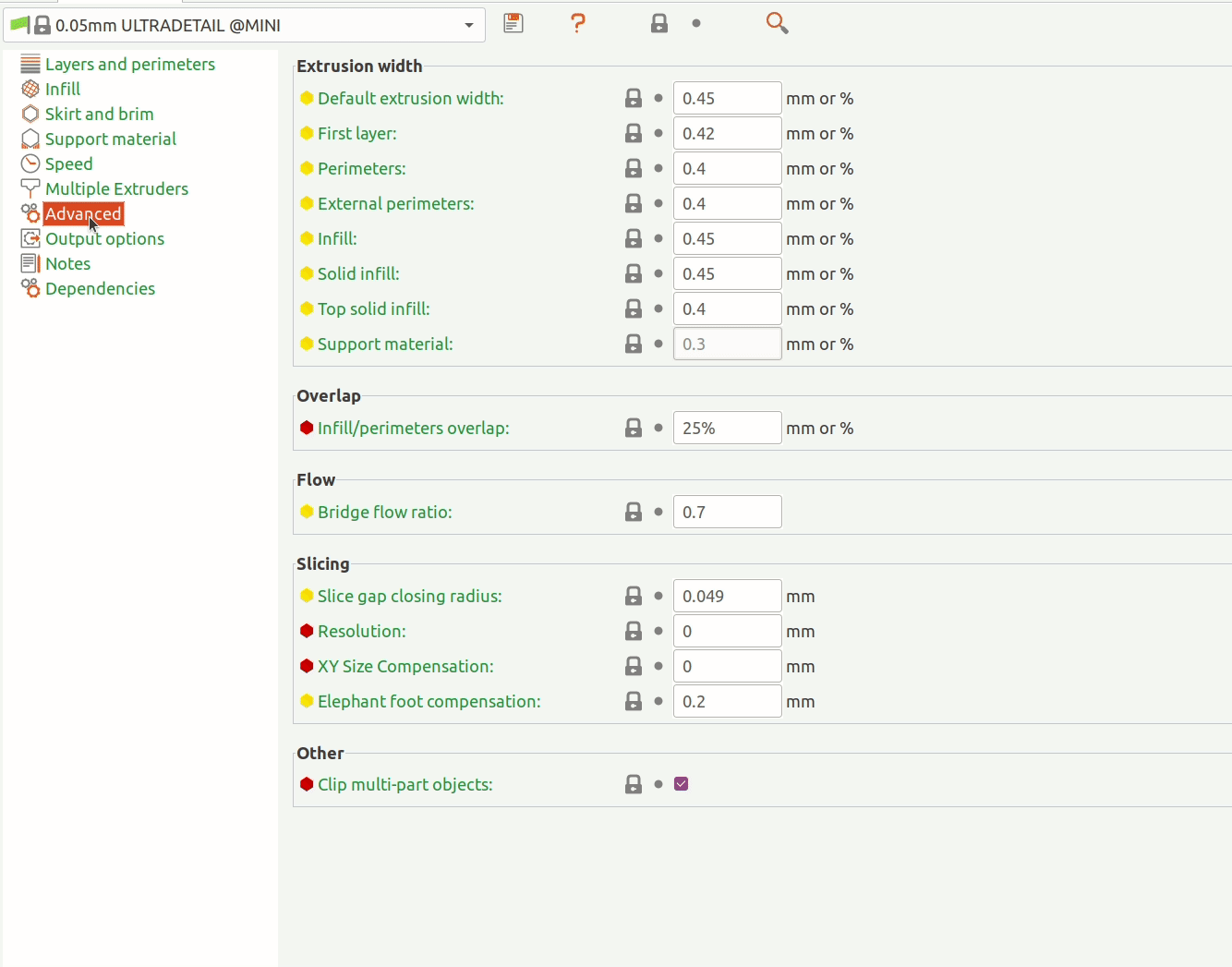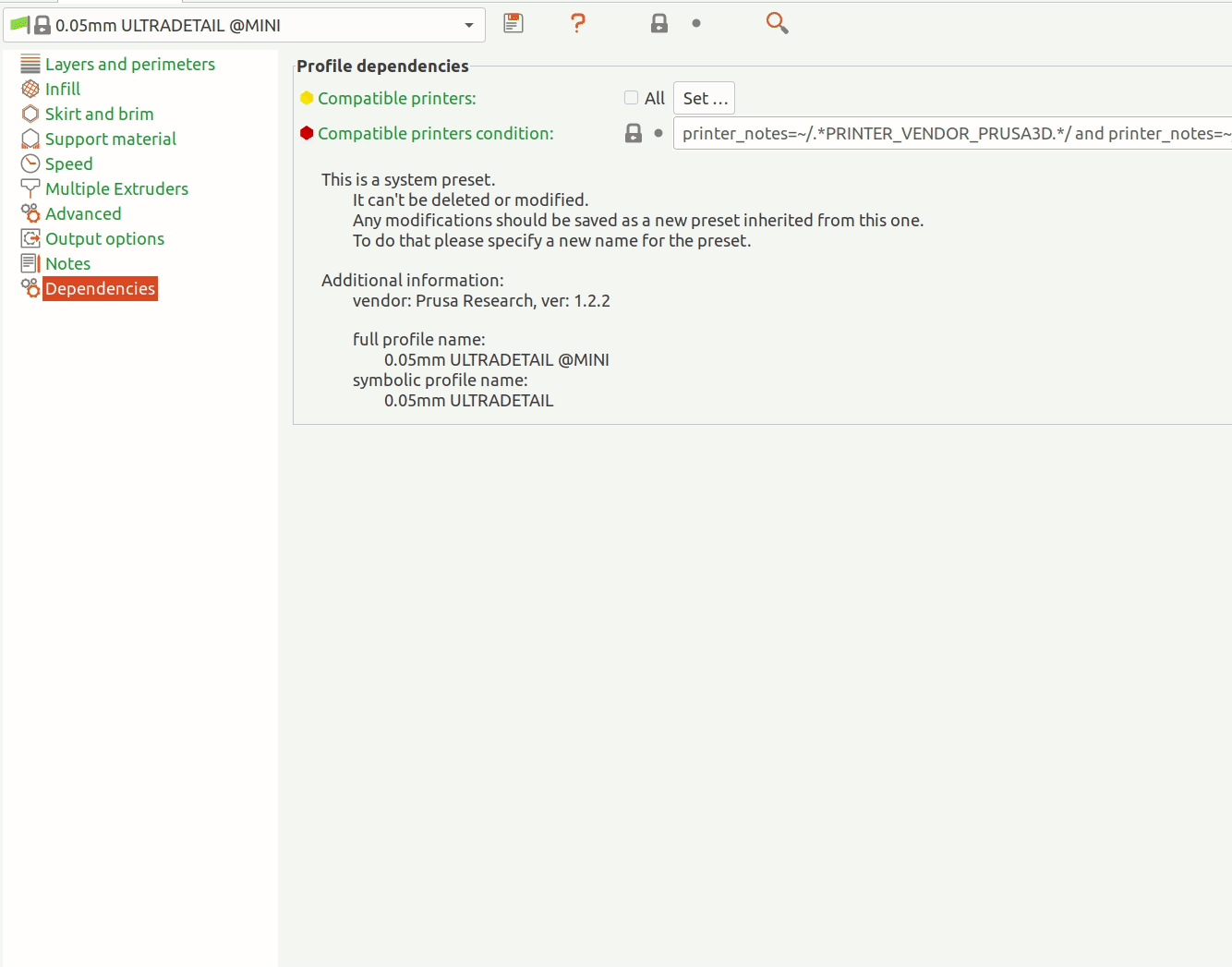
The Object Detection API uses protobuf files to configure training and evaluation (pictured below). Besides hyper-parameters, the config allows you to specify data augmentation operations (highlighted below). TFRecords are expected as input.
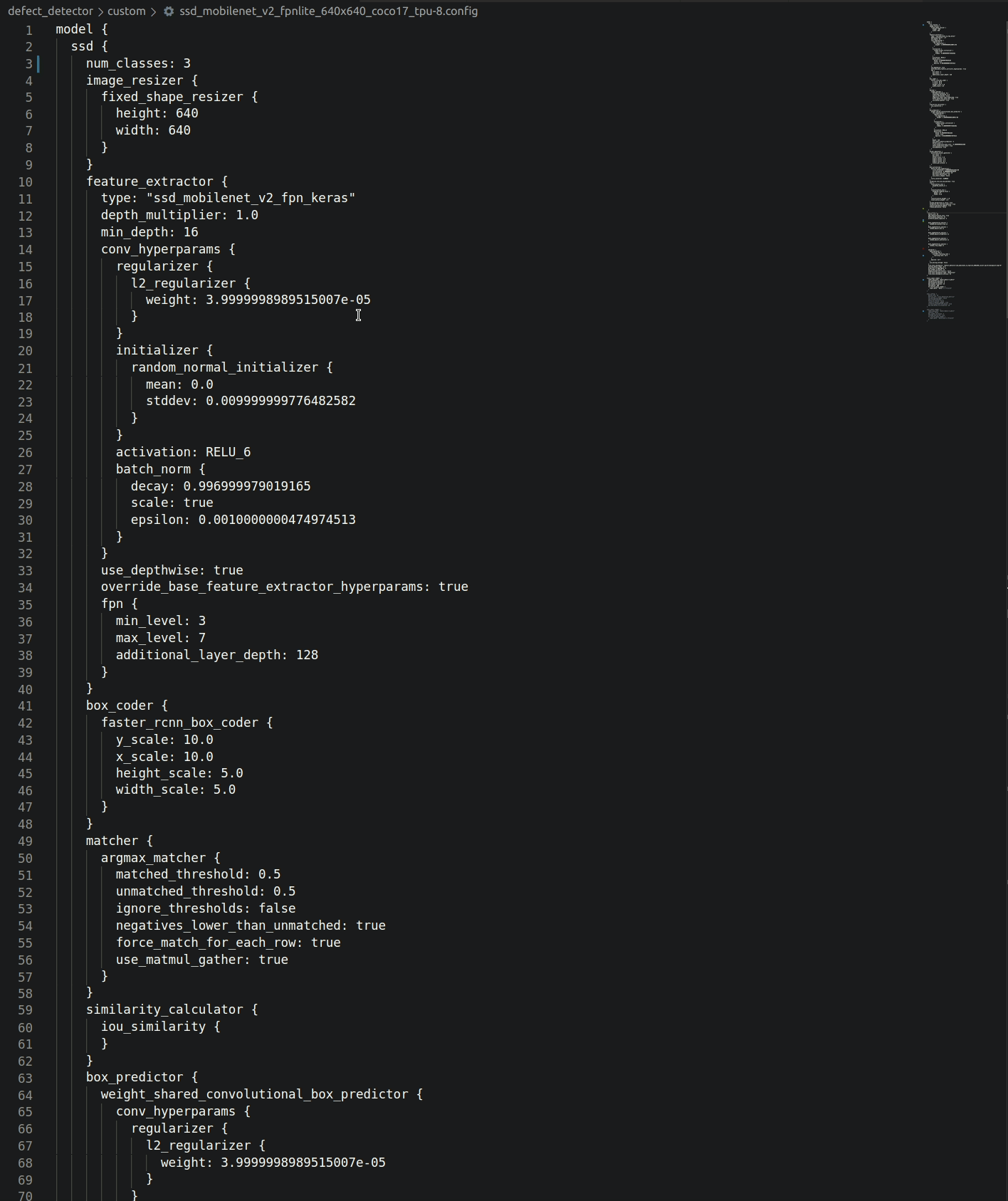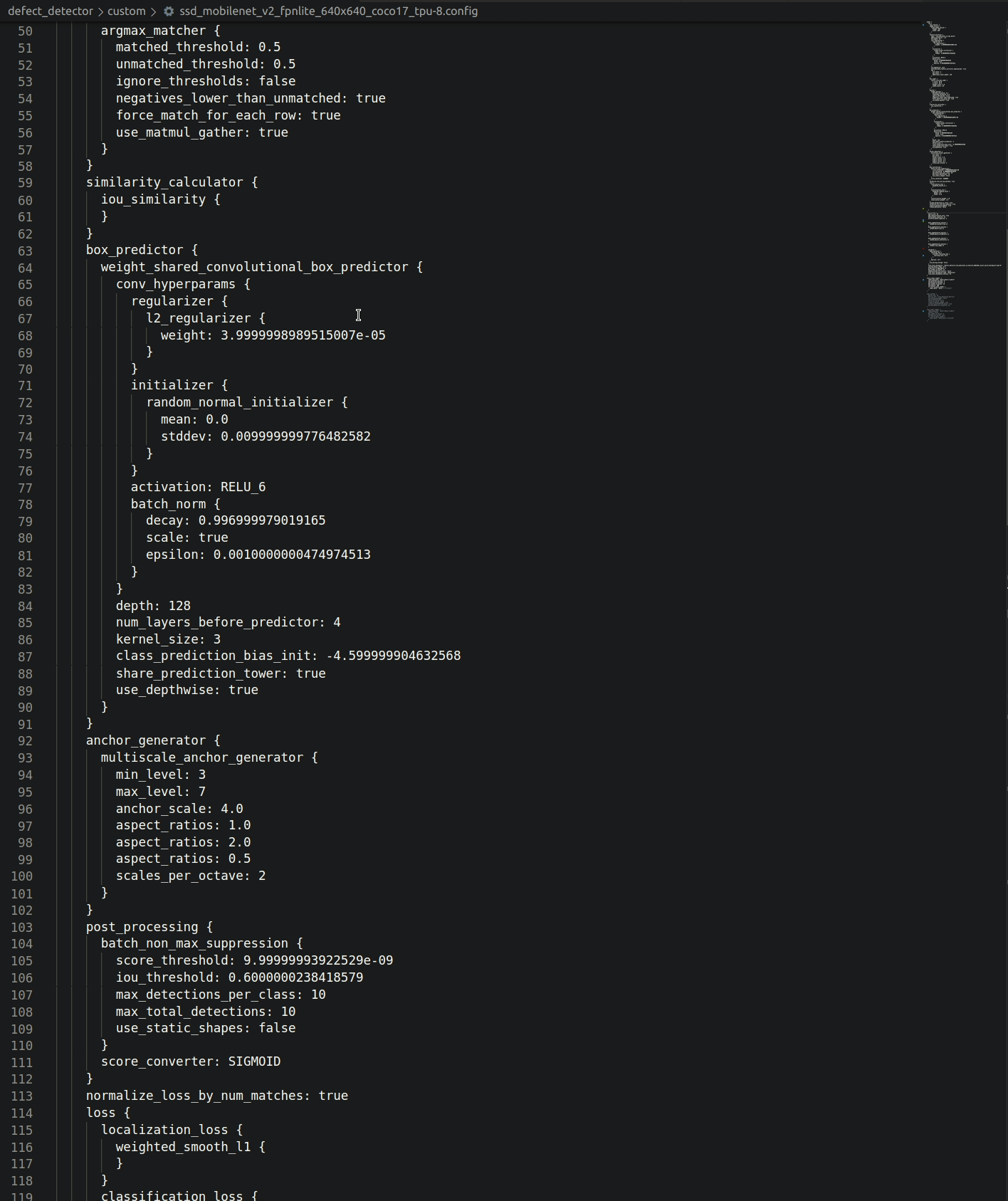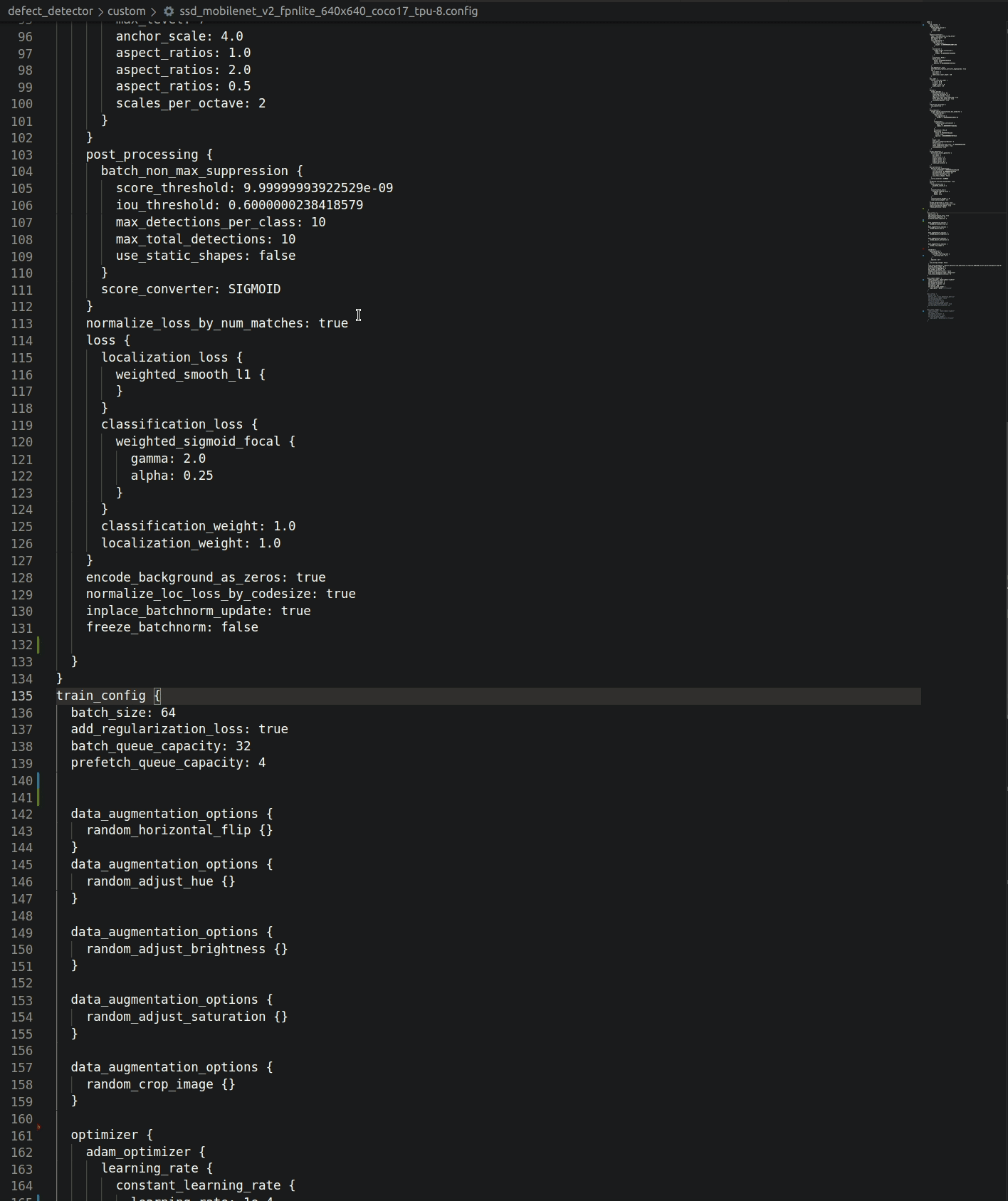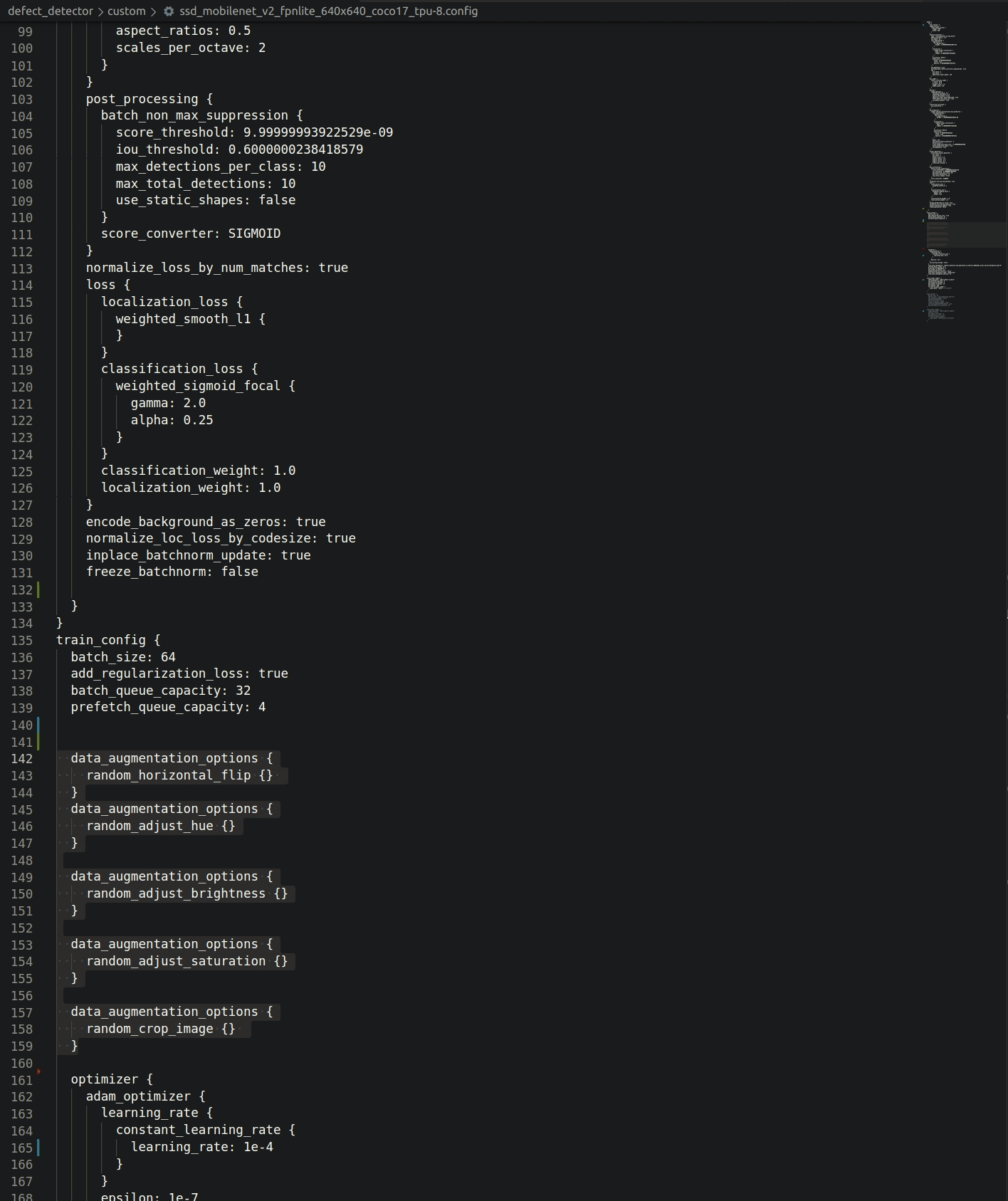
Logging parameters, metrics, artifacts with MLFlow
Do your experiments and lab notes look like this hot mess of a notebook? This is what my experiment tracking looked like when I ported AnyNet from Facebook Research's model zoo to TensorFlow 2 / Keras.
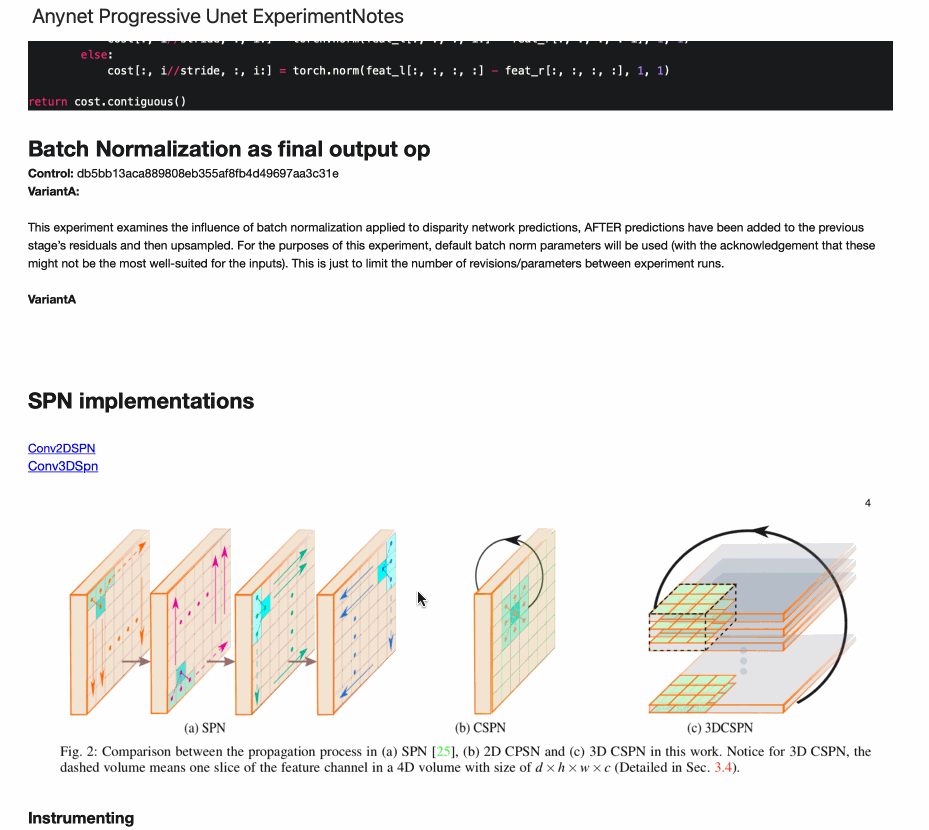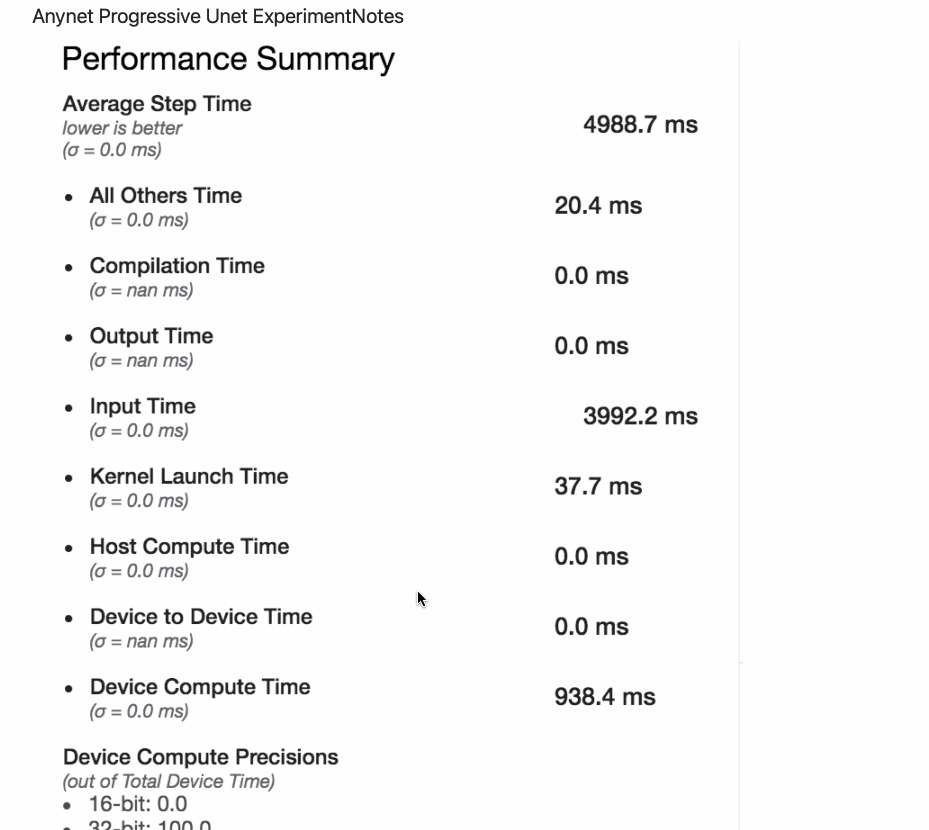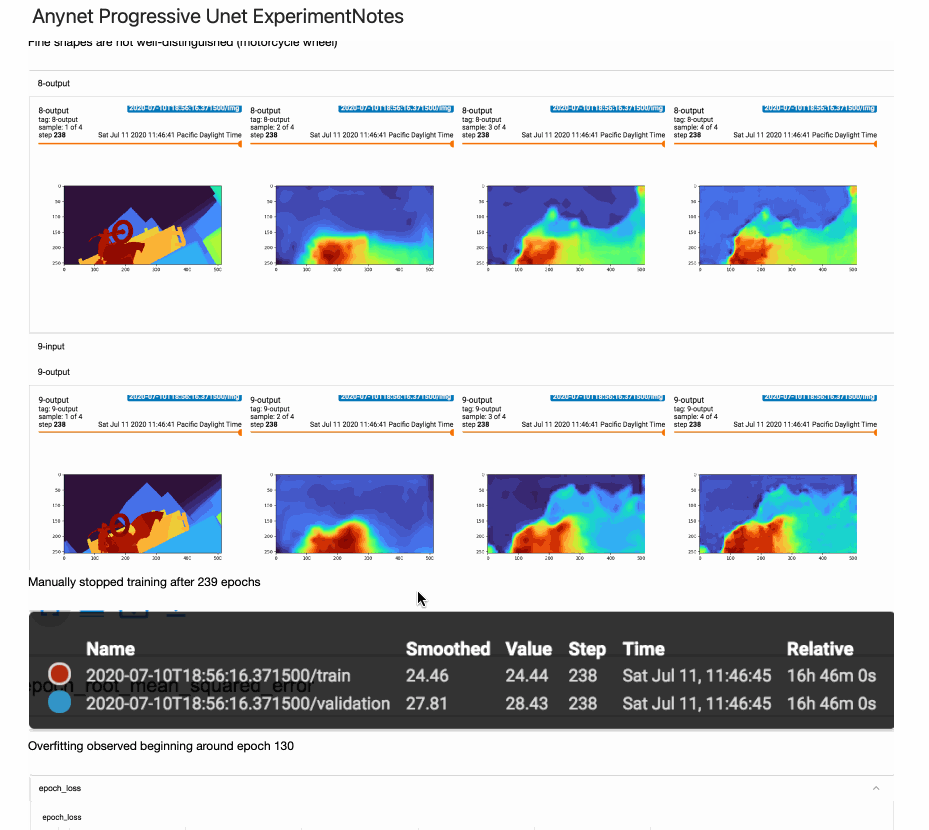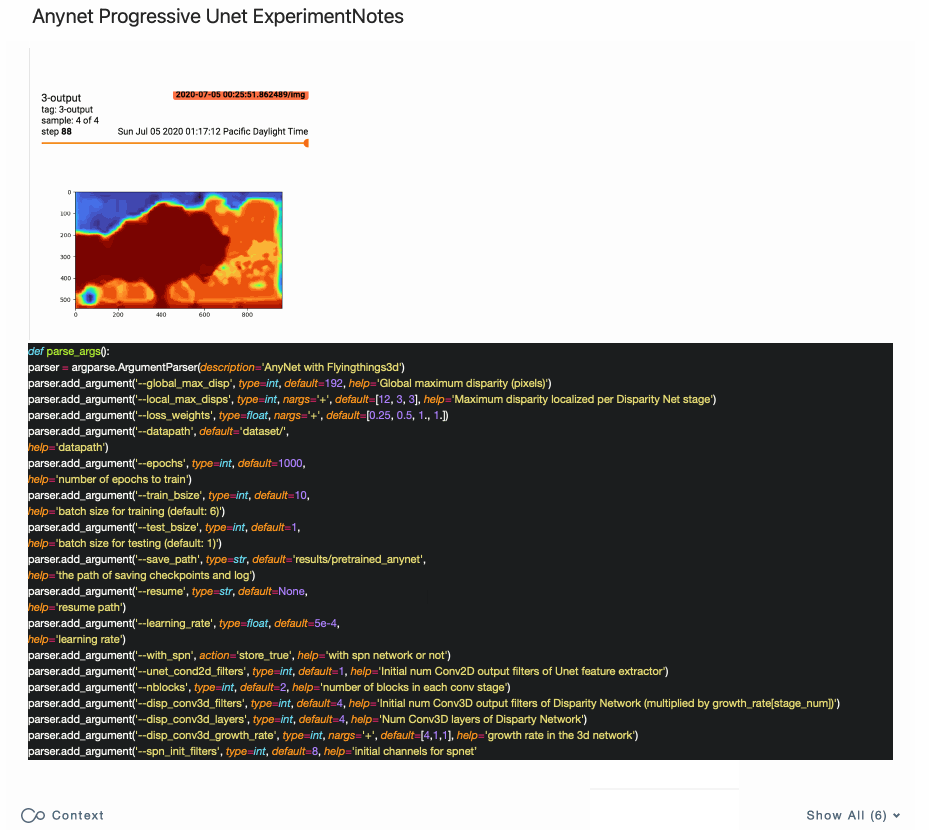
I started using MLFlow to log model hyper-parameters, code versions, metrics, and store training artifacts in a central repository. it changed my life!
Comment below if you'd like to read a deep dive into my workflow for experiment tracking and training computer vision models!
Thank you for reading! 🌻
There is no one-size-fits-all guide to building a successful machine learning system - not everything that worked for me is guaranteed to work for you.
My hope is that by explaining my decision-making process, I demonstrate where these foundational skills support a successful AI/ML product strategy.
- Data architecture - everything related to the movement, transformation, storage, and availability of data
- Software engineering
- Infrastructure and cloud engineering
- Statistical modeling
Are you interested in becoming a Print Nanny beta tester?
Click here to request a beta invite
Looking for more hands-on examples of Machine Learning for Raspberry Pi and other small devices? Sign up for my newsletter to receive new tutorials and deep-dives straight to your inbox.
Google supported this work by providing Google Cloud credit
When planning a cosplay look, it is worth considering how details related to short cosplay wigs will affect the complete look. With practical wear in mind, a comparison of details related to short cosplay wigs can clarify differences in colour and construction. To organise preparations involving details related to shoes and accessories, men's cosplay costumes for expressive character styling offers a useful starting point for practical preparation. When planning for care after the photoshoot, a balanced view of details related to photoshoot preparation can support both detail and comfort.