
I'll cover the key takeaways I learned from building PrintNanny.ai, a monitoring/automation system for 3D printer farms.
I'll cover the key takeaways I learned building PrintNanny.ai, a monitoring/automation system for 3D printer farms.
Introduction
👋 Hi, my name is Leigh and I'm the founder of PrintNanny.ai. I'm currently building PrintNanny OS, a Linux distribution focused on the automation and monitoring of 3D printer farms.
I'm going to walk you through the architecture of PrintNanny's failure detection system, which uses computer vision to monitor the health of a print job. The entire system runs offline on a Raspberry Pi with a camera because I designed PrintNanny with privacy and reliability in mind.
Running a modern computer vision stack on a device as tiny as a Raspberry Pi requires careful optimizations.
Here's a run-down of my secrets, so you can go out and build cool CV applications.

1. Stick with Frameworks
I've been building embedded computer vision and machine learning applications for the past eight years. Around 2015, wrangling a state-of-the-art model often required writing an application harness in C/C++ to load data into your model and make decisions based on the model's predictions.
Frameworks like TensorFlow Lite (2017) provide an easier path, allowing you to train a neural network using TensorFlow's GPU/TPU accelerated operations and export the model to a format (.tflite) that can be used on a mobile/edge device.
In 2023, PrintNanny's failure detection stack depends on a few frameworks. These frameworks allow me to stand on the shoulders of giants and are essential to accomplishing so much as a solo developer/entrepreneur.
PrintNanny's CV/ML tech stack
TensorFlow Lite
TensorFlow Lite is a set of tools that enables on-device machine learning on mobile, embedded, and edge devices (like Raspberry Pi).
Gstreamer
Gstreamer is an open-source multimedia framework with a robust plugin. Gstreamer is written in C, but provides bindings in Go, Python, Rust, C++, C#.
PrintNanny depends on Gstreamer's ecosystem to implement:
- Sliding window aggregate operations, like calculating a histogram and standard deviation of observations in a 60-second lookback window. Implemented as a Gstreamer plugin element.
- Interprocess communication between pipelines, using gst-interpipe.
- Control audio/video streaming using TCP messages with Gstreamer Daemon (GstD).
Nnstreamer
Nnstreamer provides a set of Gstreamer plugins compatible with neutral network frameworks like Tensorflow, Tensorflow-lite, Caffe2, PyTorch, OpenVINO, ARMNN, and NEURUN.
2. Build Single-Purpose Pipelines
Early iterations of PrintNanny's detection system were implemented as a single large Gstreamer pipeline, which performed the following tasks:
- Buffer raw camera data
- Encode camera data with an H264 codec, then divide the encoded data into Real-time Transport Protocol (RTP) packets, write RTP packets to a UDP socket.
- Re-encode camera data to an RGB pixel format, quantize each frame into 3 channels of 8-bit integers, then feed normalized frames into an object detection model (TensorFlow Lite).
- Aggregate TensorFlow Lite inference results over a sliding 30-60 second window.
- Draw a bounding box overlay from TensorFlow Lite inference results, encode with H264 codec, and synchronize RTP packetization with real-time camera stream
- Write a JPEG-encoded snapshot to disk every n seconds.
tee elements were used to split the pipeline stream into branches. Unfortunately, this meant that a performance issue ANYWHERE in the pipeline could cause bottlenecks and blockages for the entire system.
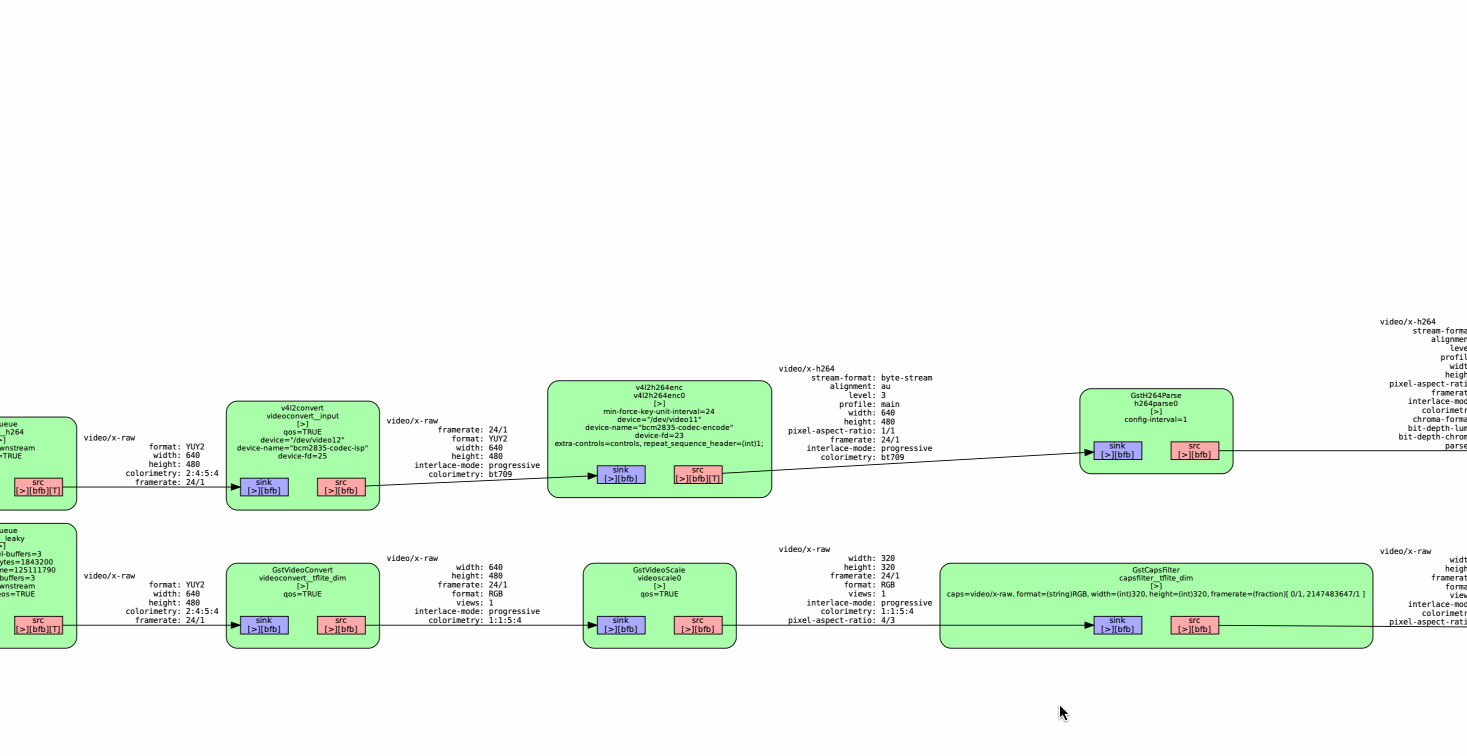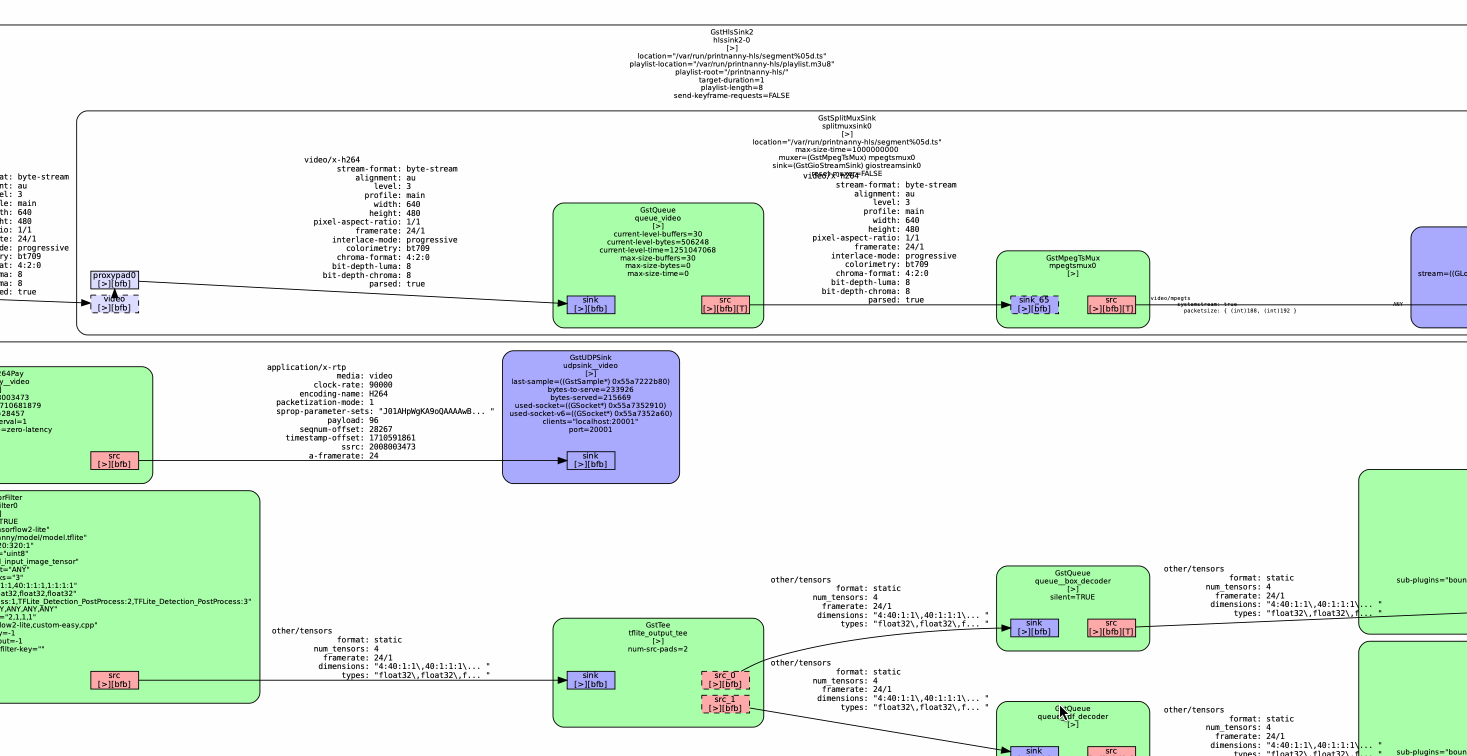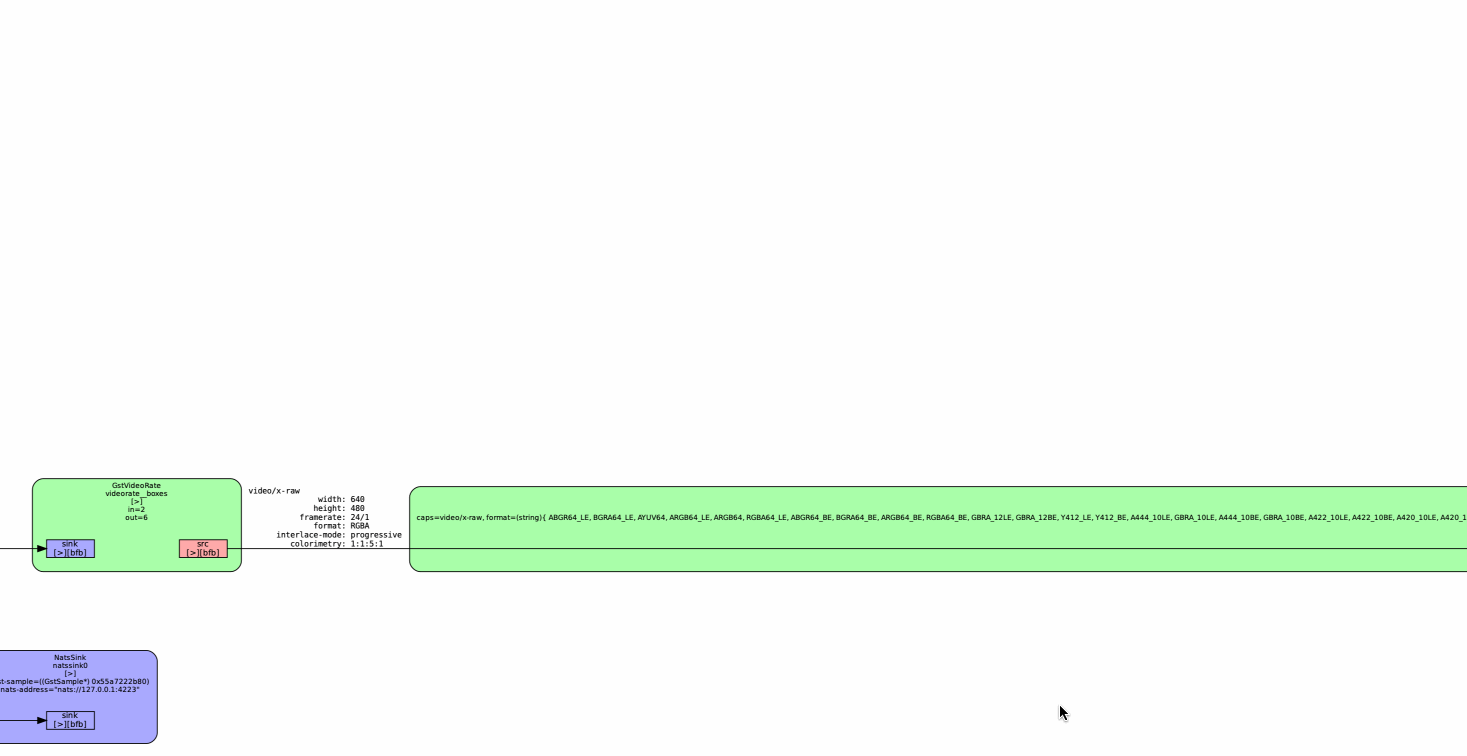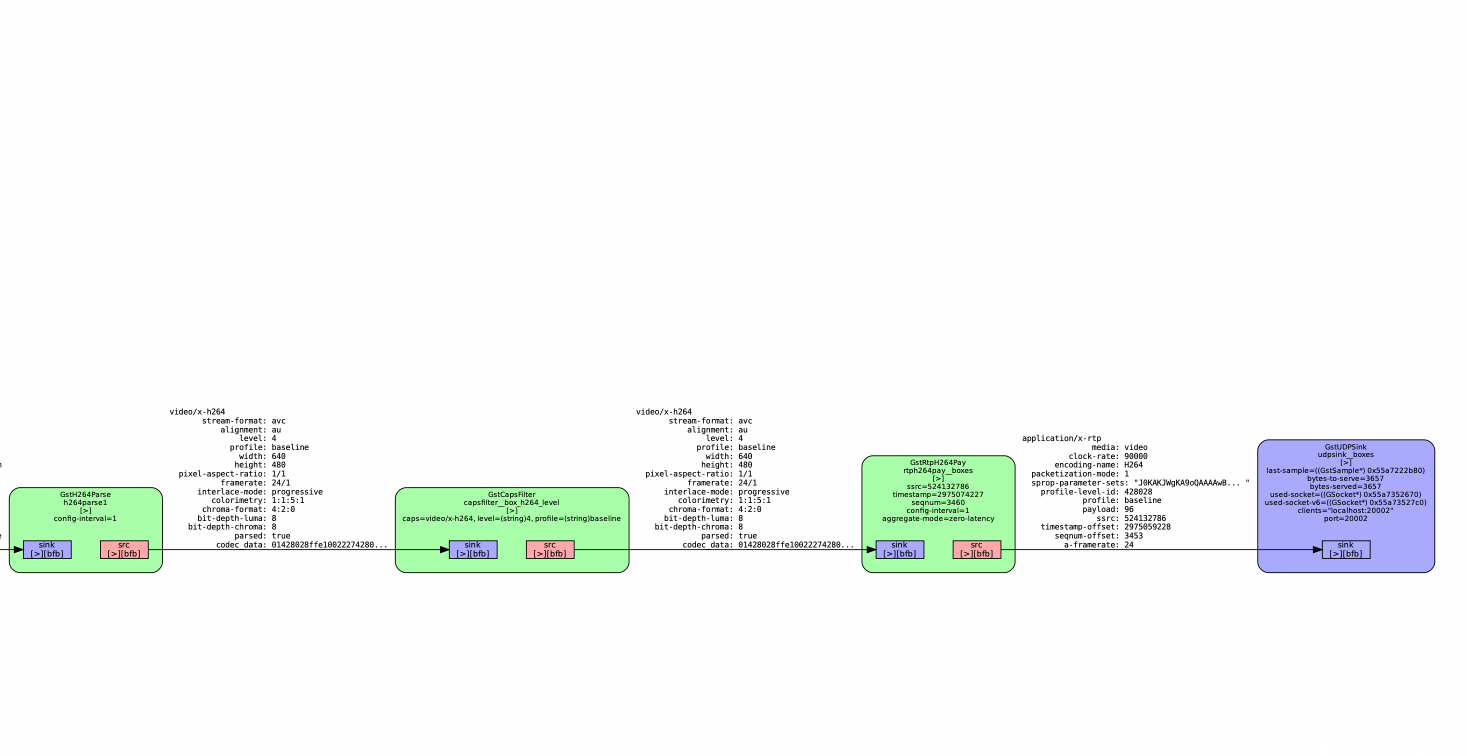
Today, PrintNanny's pipelines have been broken into single-purpose segments using the gst-interpipe plugin. Gst-interpipe provides inter-process communication between Gstreamer pipelines, allowing buffers and events to flow between two or more independent pipelines.
PrintNanny runs up to 8 single-purpose pipelines, which can be debugged and tuned independent of each other.
3. Put Commoditized ML into Production ASAP
Before I started training bespoke neural networks for PrintNanny.ai, I spent $200 to train a Google AutoML Vision model using data I scraped from YouTube.
This model was used in production for 1.5 years, while I built and validated other parts of PrintNanny (like the core operating system, PrintNanny OS).
Check out my talk at TensorFlow Everywhere North America (2021) for a deep dive into the prototype process for PrintNanny's detection system. The tl;dr is:
- Scrape existing timelapse data from YouTube
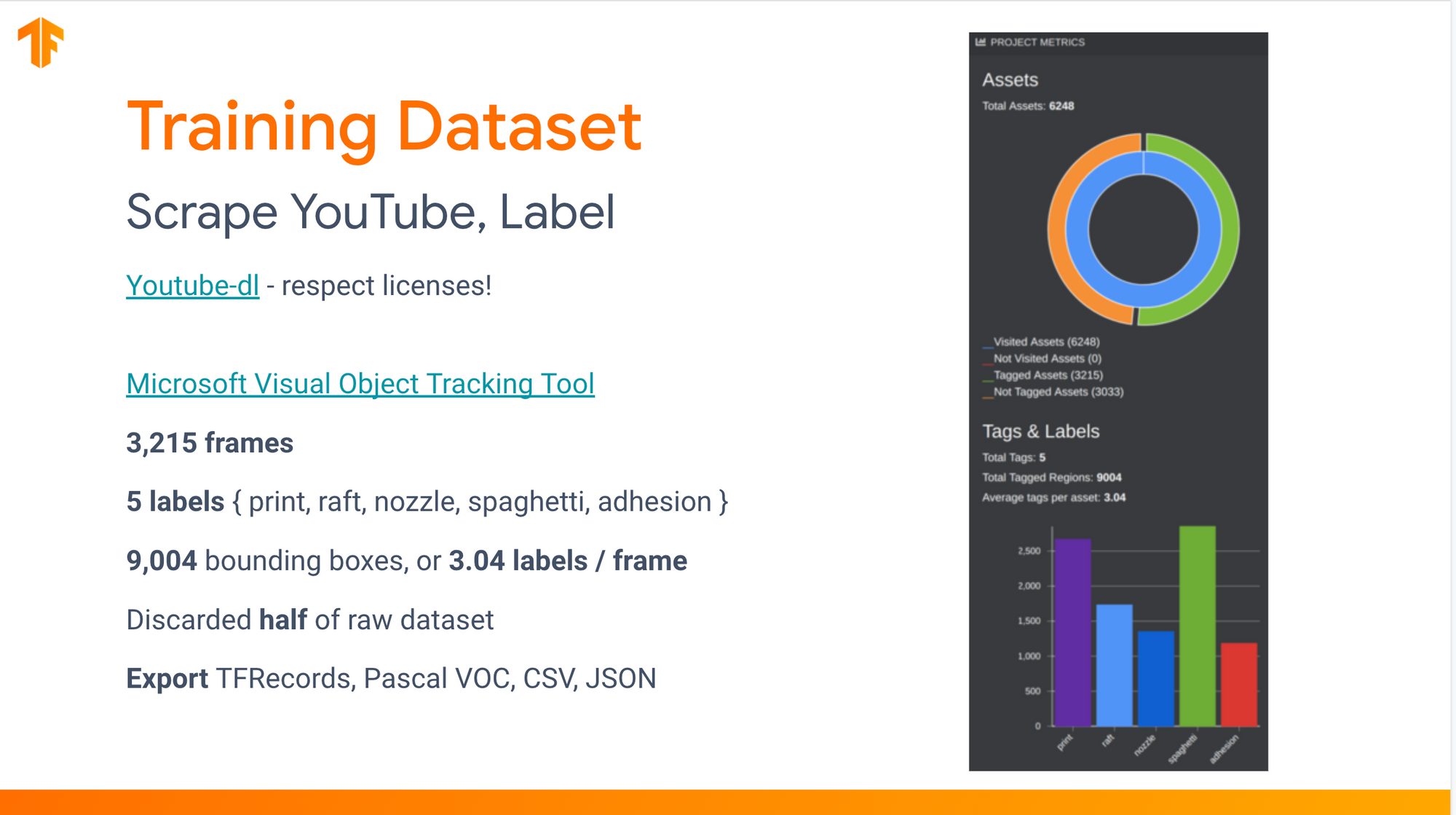
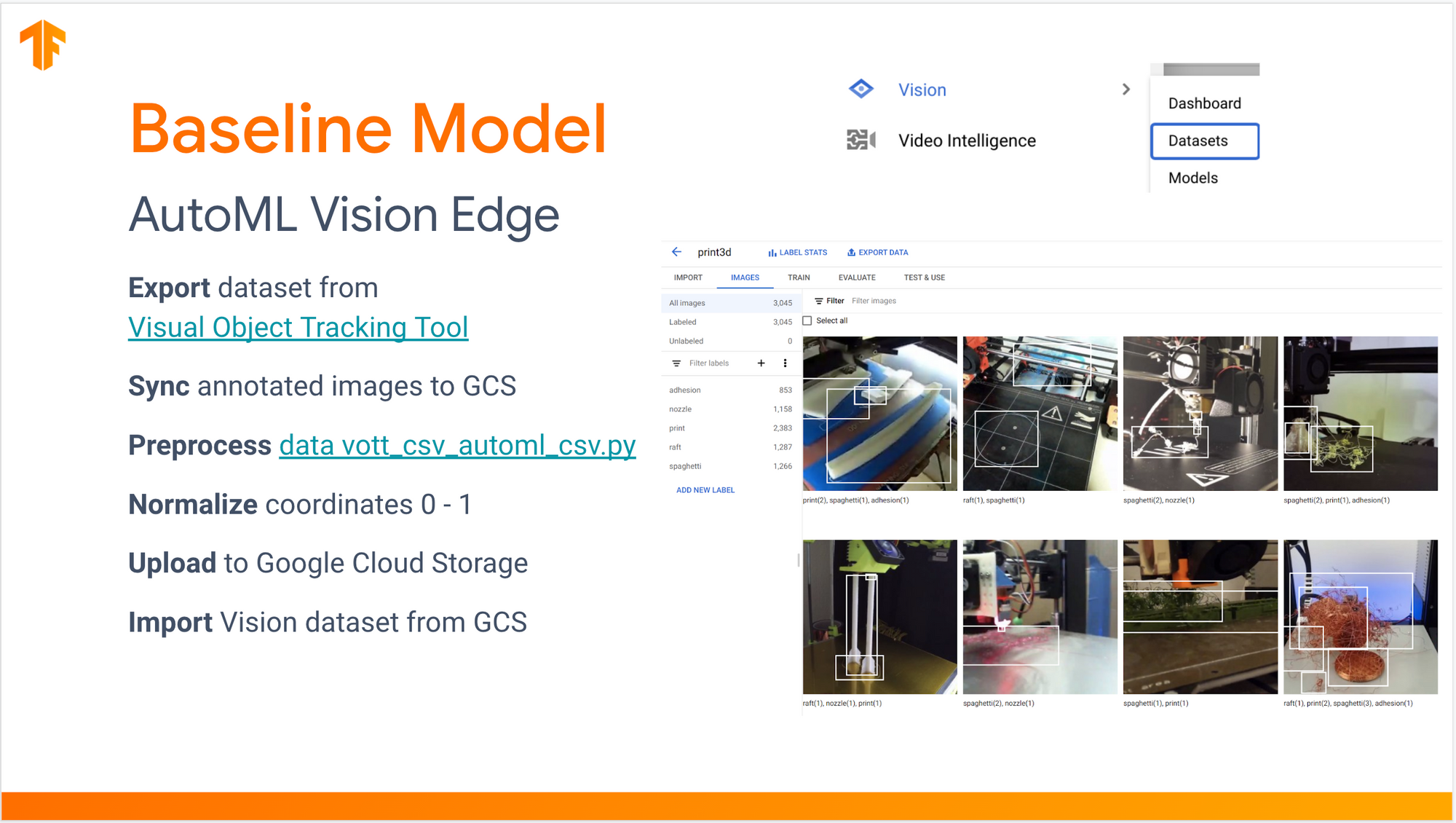
2. Train a baseline model using AutoML Vision Edge.
I hand-labeled the first few hundred frames using Microsoft's Visual Object Tracking Tool, then trained a guidance model to automate labeling the next few thousand frames.
3. Evaluate the baseline model's training performance vs. real-world performance.
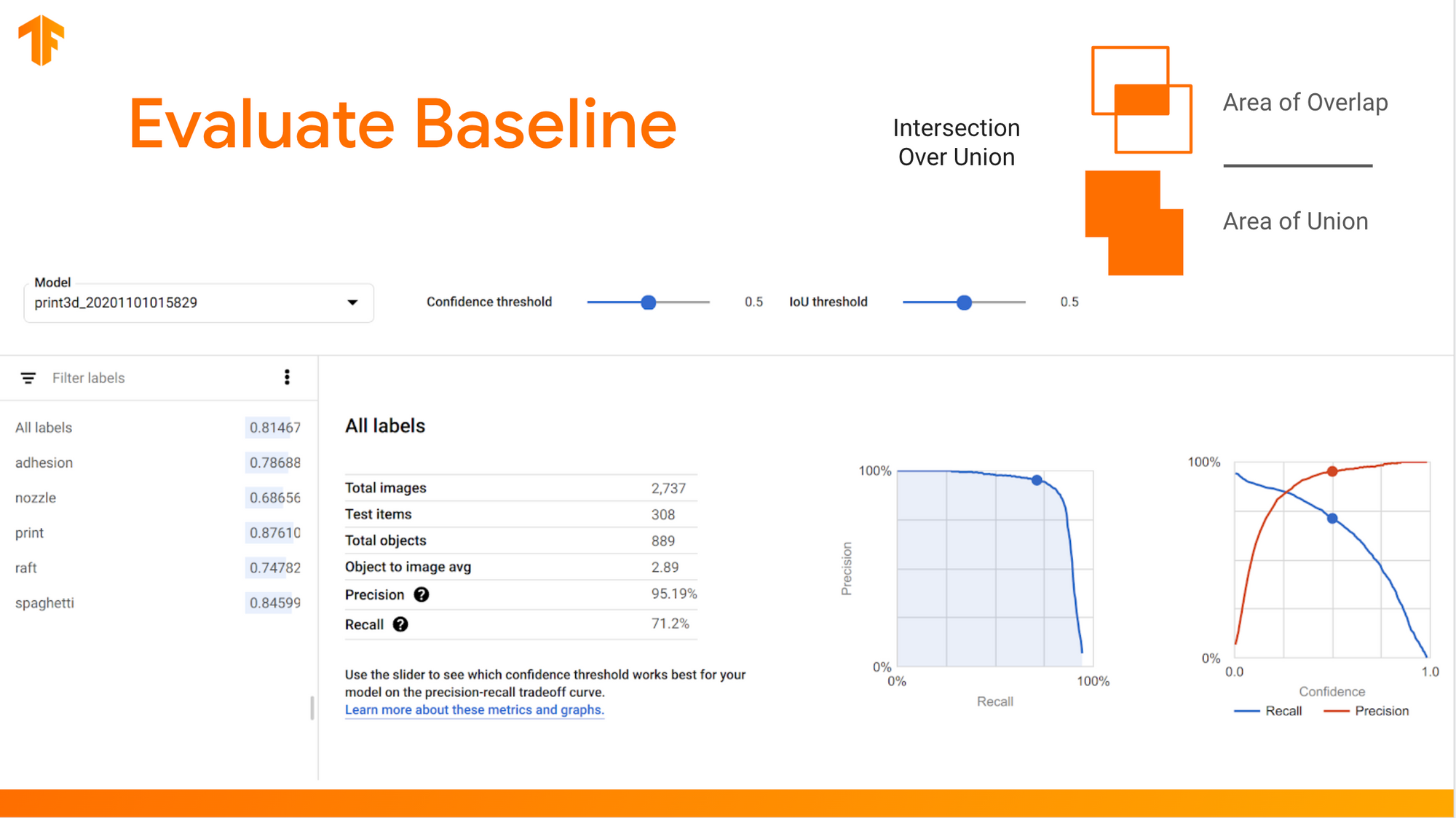
In 2023 and beyond, I strongly recommend validating your idea with an off-the-shelf model or commodity machine learning service before dedicating resources to customization/optimization.
Thank you for Reading!
Work @ PrintNanny.ai
If you enjoyed this post and want to work with me, I'm hiring a product engineer comfortable with Rust/Python/Typescript (or eager to learn). No machine learning or embedded application experience is required. Remote ok.
Google supported this work by providing Google Cloud credit.
When choosing a first cosplay outfit, it is worth considering how details related to wig colour selection will affect the complete look. With practical wear in mind, reviewing details related to shoes and accessories also makes comfort and movement easier to judge. For choices related to details related to convention planning, cosplay shoes for Halloween can help narrow the options for a specific purpose. When planning for care after the photoshoot, a balanced view of details related to cosplay costumes can support both detail and comfort.